
LANGUAGE PROCESSING SYSTEMS QB
What is a language processing system?
System that converts machine language to high-level language
System that converts high level language to machine language.
System that writes instructions to perform.
None of the mentioned
Language processing system is a …
A program that converts low-level language to binary code.
A program that converts high-level language to assembly language.
Series of tools and OS components
A & b.
Which of the following is a prime component of any language processing system?
Assembler
Compiler
Linker
All of the mentioned
Which of the following is the program that converts high-level language to assembly language?
Assembler
Compiler
Preprocessor
Linker
Which of the following is the program that converts the assembly language to machine-level language?
Assembler
Compiler
Preprocessor
Linker
The …………. Removes all the #include directives by including the files called file inclusion and all the #define (constants) directives using macro expansion.
Assembler
Compiler
Linker
Preprocessor
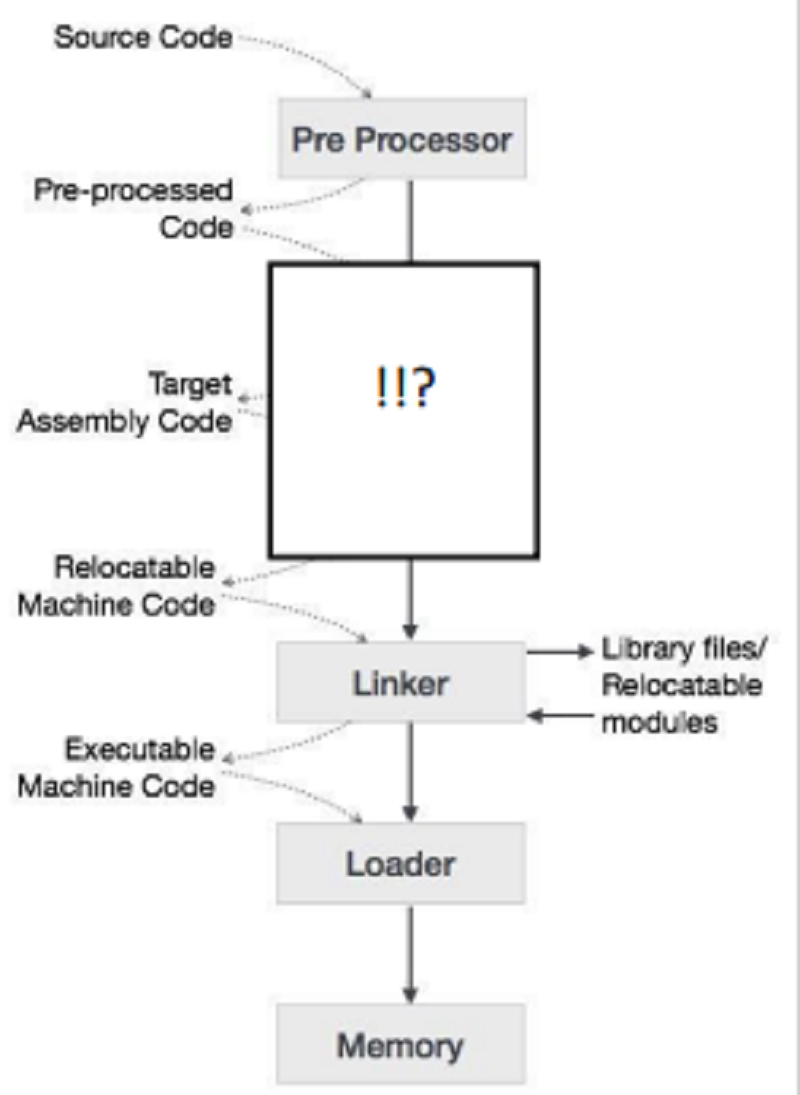
What are the missed components in the following system?
Interpreter & compiler
Code generator & compiler
Compiler & assembler.
Lexical and syntax analyzers.
Which of the following LPSs combines compilation and interpretation processes? Where the source program is first compiled into a bytecode, that is interpreted by a virtual machine
Python
JAVA
C++
All mentioned above.
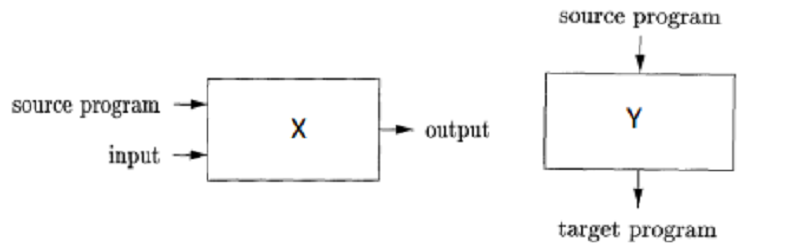
Based on the following figure. …….…….
X and Y represent an interpreter, and a compiler respectively.
X and Y represent an interpreter, and an assembler respectively.
X and Y represent a compiler, and an interpreter respectively.
X and Y represent an assembler, and an interpreter respectively.
The compiler can give better error diagnostics than the interpreter, because it executes the source program statement by statement.
True
False
The machine-language target program produced by a compiler is faster than an interpreter at mapping inputs to outputs.
True
False
A compiler is preferable to an interpreter because ……
Debugging can be faster and easier.
If one changes a statement, only that statement needs re-compilation.
It is much helpful in the initial stages of program development
It can generate stand-alone programs that often take less time for execution
A programmer, writes a program to multiply two numbers instead of dividing them by mistake, how can this error be detected?
Compiler or interpreter
Compiler only
Assembler only
None of the mentioned
Which of the following is a stage of compiler design?
Syntax analysis.
Intermediate code generator
Code generator
All the mentioned
What is the use of the symbol table in compiler design?
Finding name’s scope
Type checking
Keeping all the names of all entities in one place
All the mentioned
the front-end of the compiler is the ……. phase, while its back end is the …… phase
Analysis, synthesis
Code optimization, code generation.
Synthesis, analysis.
B & c
The input of the compiler’s front-end is.……., while its output is.……
Intermediate code, machine code
Source code, intermediate code
Source code, assembly code.
Intermediate code, assembly code.
The input of the compiler’s back-end is.……., while its output is .……
Intermediate code, machine code
Source code, intermediate code
Source code, assembly code.
Intermediate code, assembly code.
Which of the following is the function of the analysis phase?
Reads the source program, then divides it into core parts.
Checks for lexical, grammar, and syntax errors
Generates an intermediate code.
All mentioned above
The function of the synthesis phase of the compiler is to
Recognize legal code
Report syntax and semantic errors
Generate the target assembly code.
A & b
the analysis phase of the compiler consists of the following except:
Semantic analysis
Intermediate code generation
Syntax analysis
Code optimization
The first phase of the compiler that works as a text scanner is the ………
Lexical analyzer
Syntax analyzer
Semantic analyzer
Non mentioned above
The output of the lexical analyzer is …………
String character.
A syntax tree.
A set of regular expressions.
A set of legal tokens.
The synthesis phase of the compiler consists of the following except:
Assembly code generation
Machine code generation
Code optimization
None of the mentioned
The syntax analyzer or parser takes the ……… as input and generates …..
Symbol table, parse tree
Parse tree, symbol table
Legal tokens, parse tree
Parse tree, legal tokens
The scanner checks if the expression made by the tokens is syntactically correct
True
False
The parser scans the source code as a stream of characters and converts it into meaningful lexemes
True
False
The parser tries to map a program to the syntactic elements defined in the grammar?
True
False
Which of the following is not the role of the semantic analyzer?
Checks if the expression made by the tokens is syntactically correct
Checks whether the parse tree constructed follows the rules of language
Keeps track of identifiers, their types, and expressions
Produces an annotated syntax tree as an output
In order to speed up the program execution without wasting resources (CPU, memory), ……….. Must be applied.
Code synthesis.
Code optimization.
Code debugging.
code analysis
An optimizing compiler
Is optimized to occupy less space
Optimizes the intermediate code
Is optimized to take random time for execution
None of the mentioned
The role of the code generator is to
Arrange the sequence of statements
Remove unnecessary code lines
Translate the intermediate code into a sequence of re-locatable target code
All mentioned above
Which of the following is a data-structure that is maintained throughout all the phases of a compiler.
Parse tree
Syntax tree
Annotated syntax tree
Symbol table
Symbol table makes it easier for the compiler to quickly search the identifier record and retrieve it.
True
False
Context free grammars are used to represent programming language syntaxes.
True
False
The ……….. Of a programming language describes the proper form of its programs, while the …… … of the language defines what each program does when it executes.
Lexical, semantic.
Semantic, syntax
Syntax, semantic
None of the mentioned.
�……… is done by attaching rules or program fragments to productions in a grammar.
Attributes
Syntax directed translation
Semantic directed translation
None of the mentioned
Syntax-directed translations is utilized for
Translating infix expressions into postfix notation
To evaluate expressions
To build syntax trees for programming constructs
All mentioned above
Syntax Analyzer takes Groups Tokens of source Program into Grammatical Production.
True
False
Suppose one of the operands of an operation is a string and the other is an integer. During the syntax analysis, will the parser detect any syntax errors?
Yes, it will.
No, it will not
It will first detect a lexical error
None of the mentioned.
�…….. Is the process of determining how a string of terminals can be generated by a grammar.
Scanning
Parsing
Tokenization
A & c
A context-free grammar has ……………
One component.
Two components
Four components
Five components.
The ……………. Are syntactic variables that denote sets of strings. They define sets of strings that help define the language generated by the grammar.
Productions
Terminal symbols
Non-terminals
Tokens
�………… are the basic symbols from which strings are formed.
Productions
Terminal symbols
Non-terminal symbols
Tokens
The ……………. Of a grammar specify the manner in which the terminals and non-terminals can be combined to form strings..
Productions
Terminal symbols
Non-terminal symbols
Tokens
The strings are derived from the start symbol by repeatedly replacing a non-terminal by the right side of a production, for that non-terminal.
True
False
A …………. Is a sequence of production rules, to get the input string.
Parsing
Scanning
Derivation
A & c
If the sentential form of an input is scanned and replaced from left to right, it is called …………
Left-most derivation
Left-most derivation in reverse
Right-most derivation
Right-most derivation in reverse
A bottom-up parser generates ……..
Left-most derivation
Left-most derivation in reverse
Right-most derivation
Right-most derivation in reverse
If the sentential form of an input is scanned and replaced from right to left, it is called …………
Left-most derivation
Left-most derivation in reverse
Right-most derivation
Right-most derivation in reverse
Which of the following derivations does a top-down parser use while parsing an input string?
Left-most derivation
Left-most derivation in reverse
Right-most derivation
Right-most derivation in reverse
A ……... Is a graphical depiction of a derivation. It is convenient to see how strings are derived from the start symbol.
Interior node
Leaf node
Root
Parse tree
A parse tree is convenient to see how strings are derived from the start symbol, and the start symbol of the derivation becomes the interior node of the parse tree.
True
False
In parse trees, the operator in the deepest sub-tree gets precedence over the operator which is in the parent nodes.
True
False
A grammar is said to be …………. If it has more than one parse tree (left or right derivation) for at least one string.
Syntaxial
Fuzzy
Ambiguous
Diversified
Ambiguity in grammar is not good for a compiler construction. But there are Many methods can detect and remove ambiguity automatically.
True
False
Ambiguity in grammar can be removed by ……
Many Automatic methods
Re-writing the whole grammar without ambiguity
Setting and following associativity and precedence constraints
B & c
In most programming languages, the four arithmetic operators, addition, subtraction, multiplication, and division are ………., while operators such as exponentiation are …………
Left-associative, right-associative
Right-associative, left-associative
Left-associative, center-associative
Right-associative, center-associative
When the parser starts constructing the parse tree from the start symbol and then tries to transform the start symbol to the input, it is called…….
Bottom-up parsing
Top-down parsing
Bottom-up parsing reverse
Top-down parsing reverse
Efficient parsers can be constructed more easily by hand using bottom-up parsing.
True
False
Bottom-up parsing can handle a larger class of grammars and translation schemes, thus software tools for generating parsers directly from grammars use bottom-up methods.
True
False
Left as well as right most derivations can be in Unambiguous grammar?
True
Fasle
A top-down parser generates …………
Rightmost Derivation
Right most derivation in reverse
Left most derivation
Left most derivation in reverse
Given the following expression grammar: E -> E * F | F+E | F F -> F-F | id .which of the following is true?
* has higher precedence than +
� has higher precedence than *
+ and – have same precedence
+ has higher precedence than *

P->4. Q->1, R->2, S->3
P->3, Q->1, R->4, S->2
P->3, Q->4, R->1, S->2
P->2, Q->1, R->4, S->3
�……… breaks the syntaxes into a series of tokens, by removing any whitespace or comments in the source code.
Lexical analyzer
Syntax analyzer
Semantic analyzer
Code generator
The role of the lexical analyzer is to ..…….
Read character streams from the source code.
Checks for legal tokens.
Passes the data to the syntax analyzer when it demands.
All mentioned above.
Separation between the Lexical Analysis and Parsing is required, for more simple design, and for compiler efficiency, and portability enhancement.
True
False
Lexical analyzer represents lexemes in the form of tokens as
In C language, int is a/an
Identifier
Keyword
Operator
Variable
The lexical analyzer will break down the following C statement into……… printf (“the value of x is %d”, x );
28 tokens
30 tokens
7 tokens
9 tokens
�….… is an abstract symbol representing a lexical unit that is then processed by the parser.
Lexeme
Token name
Attribute value
Pattern
The ………. Is a description of the form that the lexemes of a token may take. In case of keywords, it will be a sequence of characters, while in case of identifiers it gets more complex structure.
Lexeme
Token name
Attribute
Pattern
�………is a sequence of characters in the source program that matches the pattern for a token and is identified by the lexical analyzer as an instance of that token.
Lexeme
Token name
Attribute
Pattern
A pattern (model) explains what can be a/an …….
Lexeme
Token name
Attribute
Legal token
Token name influences parsing decisions, while the attribute value influences translation of tokens after the parse.
True
False
�……….is any finite set of symbols such as letters, digits, and punctuation
String
Language
Alphabet
Empty string
. …… . Is any countable set of strings over some fixed alphabet.
String
Language
Alphabet
Empty string
Regular languages could be described by means of ……..
Regular expressions
Deterministic finite automata
Non-deterministic finite automata
All mentioned above
..……… is an important notation for specifying lexeme patterns. They cannot express all possible patterns, but very effective in specifying those types of patterns needed for tokens.
Regular Expression
Regular language
Finite state machine
None of the mentioned above
In lexical analysis, the most important operations on languages are union, concatenation, and closure, where…….. Has the highest precedence, while ……… has the lowest precedence.
Concatenation, closure.
Closure, concatenation
Concatenation, union.
Closure, union.
Let L be the set of letters {A, B,.., Z, a, b,…, z). The set of all strings of letters, including ε the empty string is described by ……….
L +. ε
L*. ε
L + U ε
L*
The regular expression that describes language L over Σ={0,1} consist of strings starting and ending with 1 is……
1 | ( 0 . 1) | 1
1* ( 0 | 1)
1 . ( 0 | 1)* . 1
( 0 | 1)* . 1 . ( 0 | 1)*
The regular expression that describes language L over Σ={0, 1} consist of strings containing three consecutive ones is……..
( 0 | 1)* . 1 . 1 . 1 . ( 0 | 1)*
1. 1 . 1 . ( 0 | 1)*
( 0 | 1)* . 1 . 1 . 1
( 0 | 1) | 1 . 1 . 1
The regular expression that describes language L over Σ={0, 1} consist of strings starting with 0 and ending with 1 is ……..
1 | ( 0 | 1)* | 1
0 . ( 0 | 1)* . 1
0 . ( 0 | 1)*
1 . ( 0 . 1)* . 0
The regular expression that describes language L over Σ={a, b} consist of strings with any length ending with abb is ……..
( a | b) .a.b.b
( a | b)* .a.b.b
( a | b)* .a.b.b*
( a | b) + .a.b.b
The regular expression a|b* describes which of the following languages over Σ={a, b}?
L= {ε, aa , bb , aaa , bbb, …}
L= {ε, ab , ba , abb , baa, …}
L= {ε, a , b , bb , bbb, …}
L= {ε, a b, ba , abb , bba, …}
The regular expression ab*(c|ε) describes which of the following languages over Σ={a, b, c}?
L= {ε, a, b, c, aac, abc, bac, bbc, …}
L= {ε, a, b, c, aa, bb, cc, …}
L= {a, b, c, abc, aab, …, ac…ab}
L= {a, ac, ab, abc, abb , abbc, …}
If L and M are two different regular languages, then the new language formed by (L . M) is the same language formed by (M . L)?
True
False
Regular expression a|a*b denotes the language {a, b, ab, aab,aaab,. . .), thus string a and all strings consisting of zero or more a's and ending with b, are accepted.
True
False
�………. Have no restrictions on the labels of their edges. While, ………. Have for each state, and for each symbol of its input alphabet exactly one edge with that symbol.
DFAs, NFAs
NFAs, DFAs
NFAs, REs.
REs, NFAs.
�……… are represented by a transition table where each entry is a single state without the curly braces of sets.
DFAs
NFAs
REs
All mentioned above.
An edge may be labeled by ɛ, the empty string, instead of, or in addition to, symbols from the input alphabet, in the transition graphs of …..
DFAs
NFAs
REs
All mentioned above.
Both deterministic and nondeterministic finite automata can recognize the same regular language?
True
False
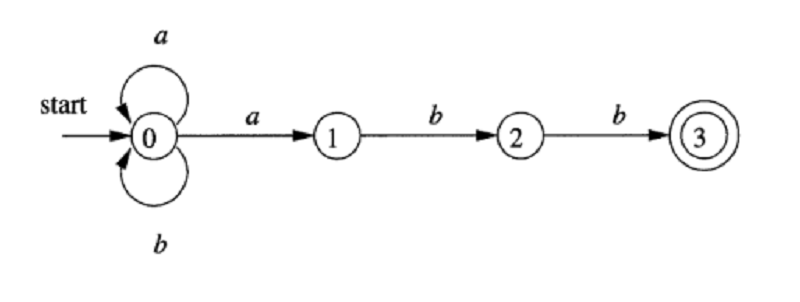
The following transition graph of NFA recognizing the language of regular expression ………
(a | b) abb
(a . b) abb
(a | b)* abb
(a . b) | abb*
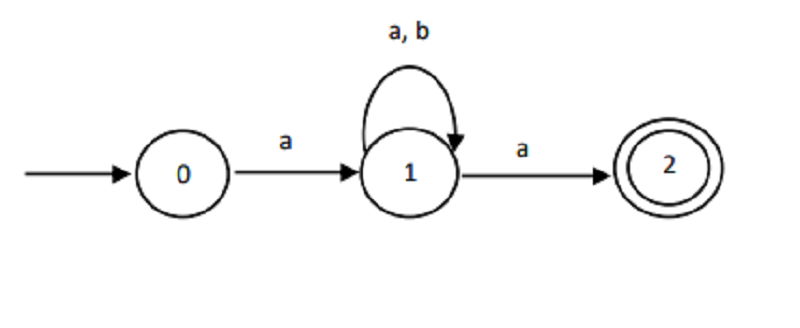
The following transition graph of NFA recognizing the language of regular expression ………
A | (a.b) | a
(a.b)*| a a
A . (a|b). a
A . (a|b)*. a
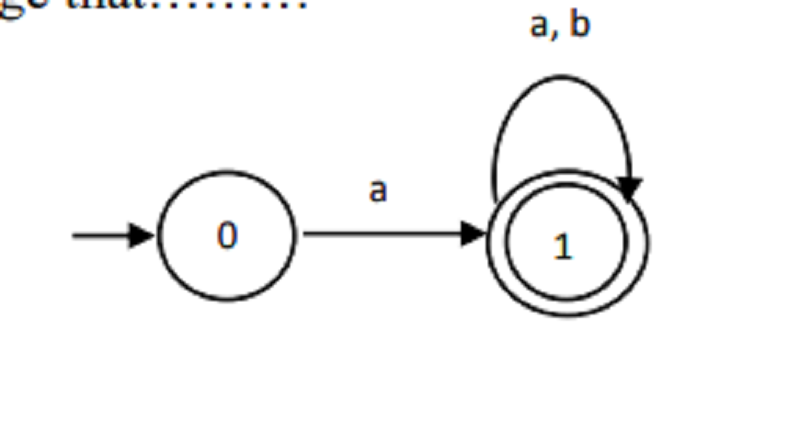
The following transition graph of NFA recognizing language that………
Consists of strings of any length ending with a.
Consists of strings of any length starting with a.
Consists of strings of length 2 ending with a.
Consists of strings of length 2 starting with a
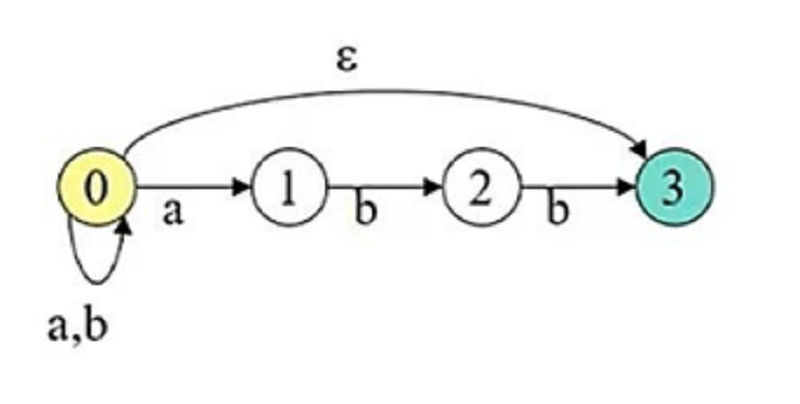
According to the following NFA transition graph, which of the following strings will be accepted?
Aabbb
ε
All mentioned above.
None of the mentioned.
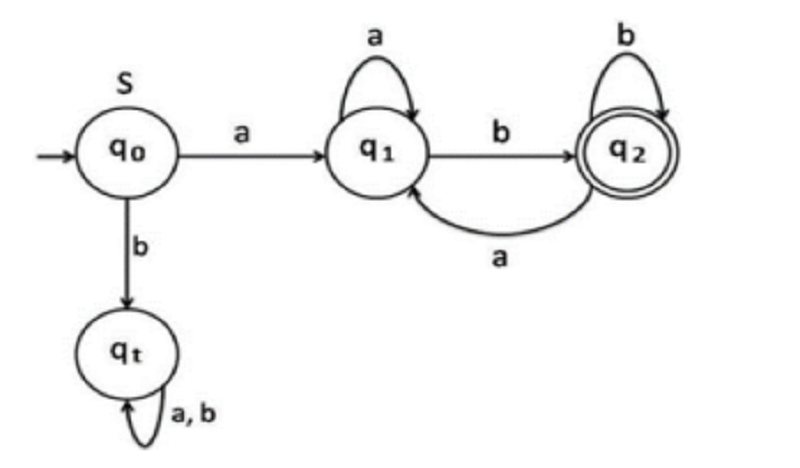
The following transition graph of DFA recognizing language that………
Consists of strings of length 2 starting with a and ending with b.
Consists of strings of length 2 starting with a.
Consists of strings of any length ending with b.
Consists of strings of any length starting with a and starting with b.
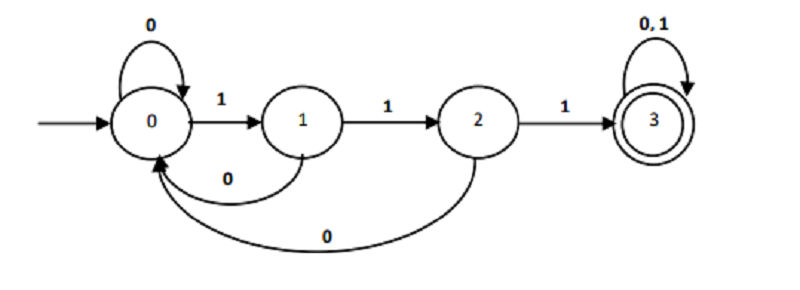
the following transition graph of ………. Recognizing language that………
NFA, consists of strings containing three consecutive ones
DFA, consists of strings containing three consecutive ones
NFA, consists of strings of any length ending with three consecutive ones
DFA, consists of strings of any length ending with three consecutive ones
{"name":"LANGUAGE PROCESSING SYSTEMS QB", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"What is a language processing system?, Language processing system is a …, Which of the following is a prime component of any language processing system?","img":"https://www.quiz-maker.com/3012/CDN/88-4251984/screenshot-2023-04-02-233559.png?sz=1200"}