
Selected topics in computers

Pattern Classification and Neural Networks Quiz
Test your knowledge of pattern classification, neural networks, and machine learning concepts with our comprehensive quiz! This quiz contains 68 carefully crafted questions designed to challenge your understanding of the selected topics in computers.
Key Features:
- Multiple choice questions
- Covers a wide range of topics
- Ideal for students and enthusiasts alike
Classification may involve spatial pattern such as ……………
A. Fingerprints
B. Speech signals
C. Weather maps
D. A and C
�………… involves ordered sequence of data appearing in time.
A. Spatial patterns
B. Electrocardiogram
C. Temporal patterns
D. B and C
In ……… Learning the output neurons of an ANN compete among themselves to become active.
B. Winner takes all
B. Hebbian
C. Widrow-Hoff
D. Supervised
In classifier, …………….. Retain the minimum no. Of data dimension while maintaining the probability of correct classification.
A. Transducer
B. Pattern vector
C. Feature vector
D. None of previous
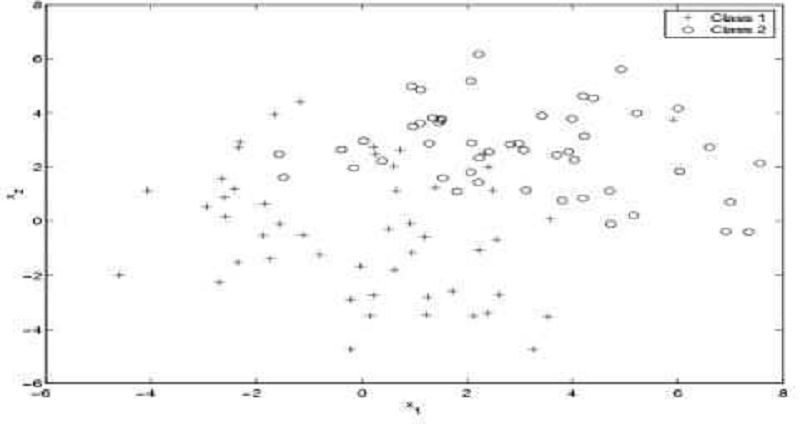
Is the following statement true or false? “A perceptron is trained on the data shown below, which has two classes (the two classes are shown by the symbols ‘+’ and ‘o’ respectively). After many epochs of raining, the perceptron will converge and the decision line will reach a steady state.”
A. True
B. False
What is a pattern vector?
B. A vector of weights w = [w1,w2, ...,wn]T in a neural network.
C. A vector of measured features x = [x1, x2, ..., xn]T of an input example.
D. A vector of outputs y = [y1, y2, ..., yn]T of a classifier.
Classification may involve spatial pattern such as ……………
A. Fingerprints
B. Speech signals
C. Electrocardiogram
D. B and C
In McCulloch-Pitts model, the weighted sum of signals for neuron to fire needs to be ……………. Threshold value (T).
A. Equal
B. Exceed by
C. More than
D. A or C
ANN when they do not contain any memory element are classified as …………………
A. static
B. dynamic
C. classic
D. stationary
�………… is a class assignment for input patterns that are identical used for training ANN.
A. Recognition
B. Classification
C. Identification
D. A and B
�………… is a class assignment for input patterns that are not identical used for training ANN.
B. Recognition
B. Classification
C. Identification
D. A and B
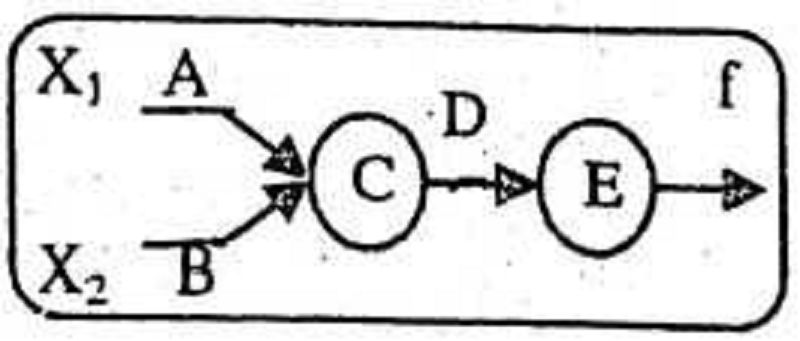
For the MCculloch-Pitts Neuron model shown in the opposite Fig. To get the function 𝒇 = (̅𝒙̅𝟝̅̅𝒙̅𝟝̅) the weights and the thresholds A, B, C, D, E must be:
A. 1, 1, 1, -1, 0
B. -1, 1, 1, 1, 1
C. 1, 1, 2, -1, 0
D. -1, -1, 2, -1, 0
Teacher presents a Pass/Fail indication only in …………. Learning.
A. Supervised
B. Unsupervised
C. Reinforced
D. Competitive
What is the biggest difference between Delta Rule and the Perceptron Learning Rule for learning in a single-layer feedforward network?
A. The Delta Rule is defined for step activation functions, but the Perceptron Learning Rule is defined for linear activation functions.
B. The Delta Rule is defined for sigmoid activation functions, but the Perceptron Learning Rule is defined for linear activation functions.
C. The Delta Rule is defined for linear activation functions, but the Perceptron Learning Rule is defined for step activation functions.
D. The Delta Rule is defined for sigmoid activation functions, but the Perceptron Learning Rule is defined for step activation functions.
In the recognition and classification system…….. Perform reduction of …….. dimensionality.
A. Feature extractor, feature space
B. Classifier, feature space
C. Transducer, Pattern space
D. Feature extractor, Pattern space
For linearly separable patterns, classifier may use………………
A. Nonlinear discriminant functions
B. Multilayer ANN
C. Linear discriminant functions
D. A or B
In a dichotomizer, input patterns with no membership to any category are characterized by decision surface equation as:
A. 𝑔1(𝑥) < 𝑔2(𝑥)
B. 𝑔1(𝑥) > 𝑔2(𝑥)
C. 𝑔1(𝑥) = 𝑔2(𝑥)
D. None
In Competitive learning, weights are updated based on the input pattern alone, this is due to:
A. Cluster center position=input vector connected to the corresponding output unit.
B. Weight vectors rotation toward the centers of the input clusters until the input data is divided into disjoint clusters.
C. The following equation w(t+1)=w(t) +(x(t)*w(t)).
Which of the following statements is NOT true for a minimum distance classifer (MDC)?
A. The MDC is specified completely by the prototype vectors for all M classes in a classification problem.
B. The MDC minimizes the average loss of misclassifying the input patterns.
C. The MDC makes a decision boundary between two classes. This boundary is a line, plane or hyper plane where the two decision functions are equal.
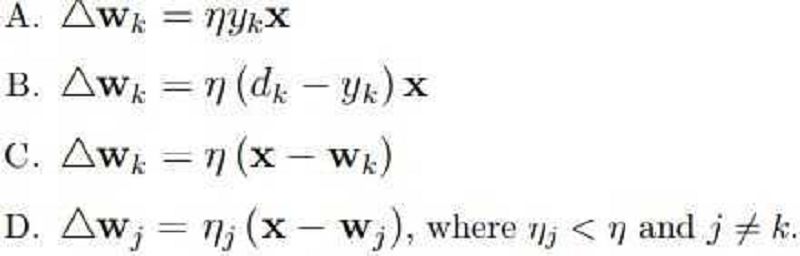
Which of the following equations is the best description of the Perceptron Learning Rule?
A.
B.
C.
D.
Is the following statement true or false? “A cluster is a group of patterns that have similar feature values.”
A. TRUE.
B. FALSE.
Why is the XOR problem exceptionally interesting to neural network researchers?
A) Because it can be expressed in a way that allows you to use a neural network
B) Because it is complex binary operation that cannot be solved using neural networks
C) Because it can be solved by a single layer perceptron
D) Because it is the simplest linearly inseparable problem that exists.
Why are linearly separable problems of interest of neural network researchers?
A) Because they are the only class of problem that network can solve successfully
B) Because they are the only class of problem that Perceptron can solve successfully
C) Because they are the only mathematical functions that are continue
D) Because they are the only mathematical functions you can draw
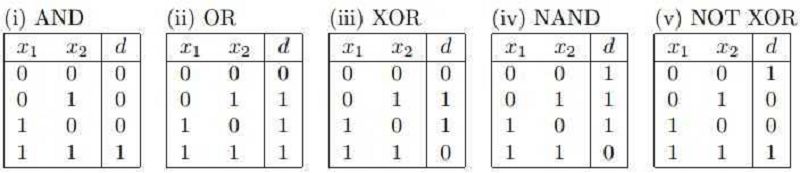
Which of the following 2 input Boolean logic functions are linearly inseparable (that is, NOT linearly separable)?
A. (i), (ii), and (iv)
B. (ii) and (iii)
C. (iii) only
D. (iii) and (v)
A perceptron with a unipolar step function has two inputs with weights w1 = 0.5 and w2 = −0.2, and a Threshold T= 0.3. For a given training example x = [𝟎 𝟝]𝑻, the desired output is 1. Does the perceptron give the correct answer?
A. Yes.
B. No.
What is a feature in a pattern classification problem?
A. An output variable.
B. An input variable.
C. A hidden variable or weight.
What is a decision boundary in a pattern classification problem with two input variables?
A. A histogram defined for each image in the training set.
B. A line or curve which separates two different classes.
C. A plane or hypercurve defined in the space of possible inputs.
What is a statistically optimal classifier?
A. A classifier which calculates the nearest neighbour for a given test example.
B. A classifier which gives the lowest probability of making classification errors.
C. A classifier which minimises the sum squared error on the training set.
How are the prototype vectors calculated in a minimum distance classifier?
A. For each class, calculate the mean vector from the input vectors in the training set.
B. For each class, calculate the covariance matrix from the input vectors in the training set.
C. For each class, calculate the prior probability from the input vectors in the training set.
A neuron with 4 inputs has the weight vector w = [𝟝, 𝟝, 𝟑, 𝟒]𝑻 and a bias b = 0 (zero). The activation function is linear, where the constant of proportionality equals 2 that is, the activation function is given by f (net) = (2*net). If the input vector is x =[𝟒, 𝟖, 𝟓, 𝟔]𝑻, then the output of the neuron will be
A. 1.
B. 59.
C. 112.
D. 118.
What is the biggest difference between Widrow & Hoff’s Delta Rule and the Perceptron Learning Rule for learning in a single-layer feed forward network?
A. The Delta Rule is defined for step activation functions, but the Perceptron Learning Rule is defined for linear activation functions.
B. The Delta Rule is defined for sigmoid activation functions, but the Perceptron Learning Rule is defined for linear activation functions.
C. The Delta Rule is defined for linear activation functions, but the Perceptron Learning Rule is defined for step activation functions.
D. The Delta Rule is defined for sigmoid activation functions, but the Perceptron Learning Rule is defined for step activation functions
Is the following statement true or false? “The XOR problem can be solved by a multi-layer perceptron, but a multi-layer perceptron with linear activation functions cannot learn to do this.”
A. TRUE.
B. FALSE.
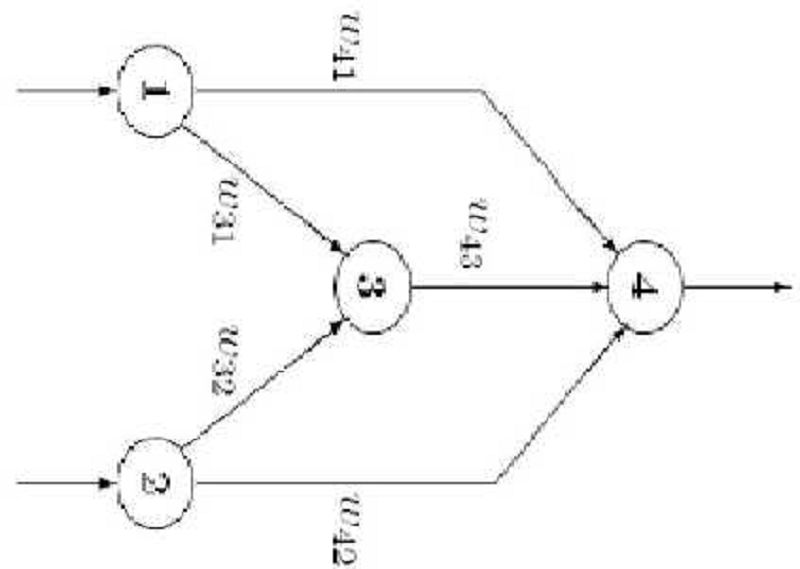
For the next multi-layer perceptron with binary input-output and unipolar functions w31=w32=w41=w42=1, w43 = -3. The threshold of the hidden unit (3) is 1.5 and the threshold of the output unit (4) is 0.5. Which of the following Boolean functions can be computed by this network?
A. AND.
B. OR.
C. XOR.
D. None of the above answers.

Use the McCulloch-Pitts model neuron. The logic functions that are implemented by networks in opposite fig is
A) 𝑋 ̅ 1+ 𝑋 ̅ 2 + 𝑋3
B)𝑋 ̅ 1. 𝑋 ̅ 2. 𝑋3
C)(𝑋 ̅ 1. 𝑋 ̅ 2) + 𝑋3
D) others
A perceptron has input weights w1 = 3.1 and w2 = 1.9 and a threshold value T = 0.4. What output does it give for the input x1 = 1.2, x2 = 2.3?
A. 8.09.
B. 8.09 – 0.4 = 7.69.
C. 0.
D. +1.
Н��𝝨𝝫 𝝱𝟝 = [𝟝 𝟝 − 𝟝 − 𝟝]𝝭, 𝝝𝟝 = 𝟝, 𝝱𝟝 = [𝟎 𝟝 − 𝟑 𝟝]𝝭, 𝝝𝟝 = −𝟝, 𝝂 = 𝟝, using perceptron learning rule & sign function and 𝝰𝟑 = [𝟝 𝟝 𝟒 − 𝟕]𝝭. Determine the weights: 𝒘𝟝 𝒂𝒅 𝒘𝟝 (let 𝒘𝟑 ≠ 𝒘𝟝 ≠ 𝒘𝟝).
A) w1 = [2 − 3 2 − 5]t, w2 = [0 1 2 − 1]t
Н��) w1 = [2 3 − 2 − 5]t, w2 = [0 1 2 − 1]t
Н��) w2 = [2 3 − 2 − 5]t, w1 = [0 1 2 − 1]t
D) Others
For the previous question what is the value of 𝒘𝟒.
A) w4 = [4 3 0 − 11]t
B) w4 = [2 3 − 2 − 5]t
C) w4 = [2 1 4 − 7]t
D) Others
A perceptron with a unipolar step function has two inputs with weights w1 = 0.5 and w2 = −0.2, and a W3= 0.3 (where W3 is the weight for bias with an activation of -1). For a given training example x = [𝟎 𝟝]𝑻, the desired output is 1, using a learning rate 𝝝 = 0.5. What are the new values of the weights and the bias after one step of training with the input?
A. w1 = 0.5, w2 = − 0.2, w3= 0.3.
B. w1 = 0.5, w2 = − 0.3, w3= 0.2.
C. w1 = 0.5, w2 = 0.3, w3= − 0.2.
D. w1 = 0.5, w2 = 0.3, w3= 0.7.
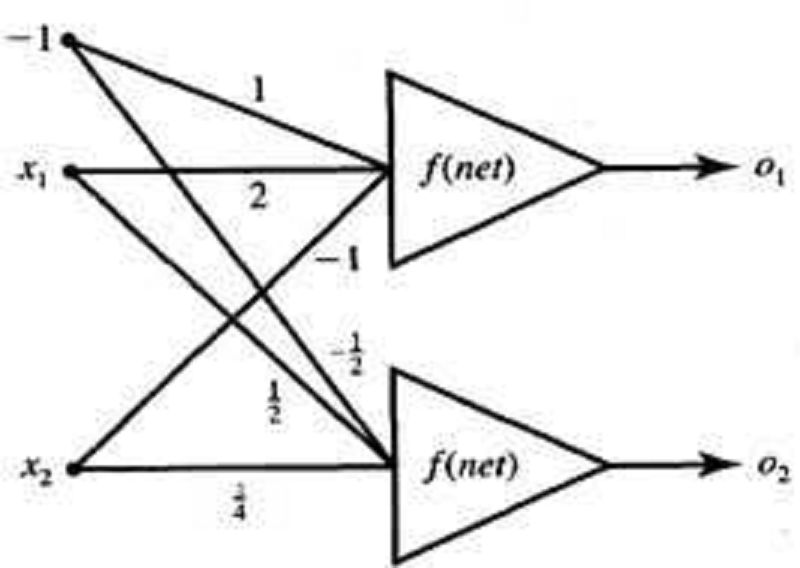
The network in opposite fig. Uses neurons with a bipolar continuous activation function with λ =1. The neuron's output has been measured as 𝑶𝟝= 0.28 and 𝑶𝟝= −0.73. The value of input 𝝗𝟝 is ??
A) −1.96
B) 1.96
C) −5.5
D) 5.5
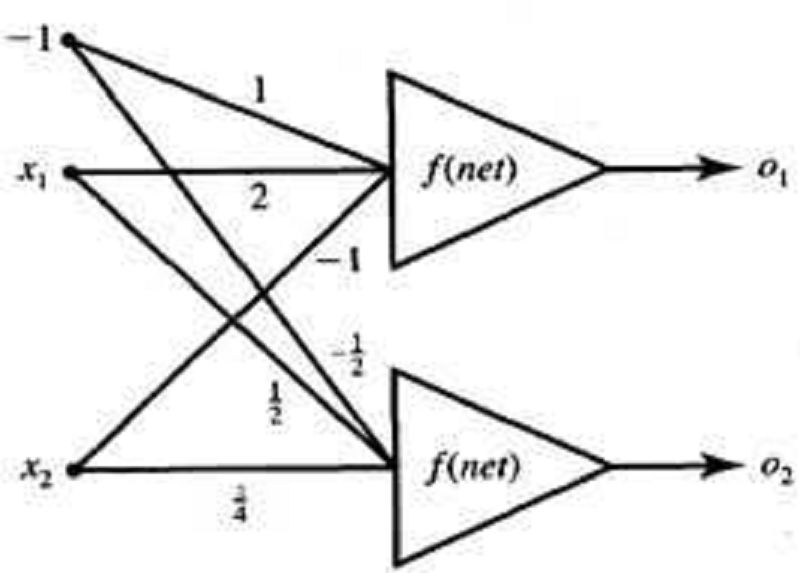
For the above question, the value of input X2…??
A) −1.96
B) 1.96
C) −5.5
D) 5.5
The weight vectors of the four units are given as follows: w1 = [−𝟝. 𝟎𝟎, −𝟝. 𝟓𝟎, 𝟎. 𝟓𝟎]𝑻 w2 = [𝟝. 𝟎𝟎, −𝟝. 𝟎𝟎, 𝟓. 𝟝𝟎]𝑻 w3 = [𝟝. 𝟓𝟎, 𝟔. 𝟎𝟎, 𝟒. 𝟑𝟎]𝑻 w4 =[−𝟒. 𝟎𝟎, 𝟕. 𝟎𝟎, 𝟎. 𝟔𝟎]𝑻. An input vector x = [−𝟝. 𝟒𝟎, 𝟝. 𝟑𝟎, 𝟎. 𝟝𝟎]𝑻 is presented to the network. Which unit is the winning neuron?
A. Unit 1.
B. Unit 2.
C. Unit 3.
D. Unit 4.
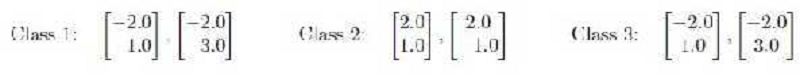
Design a minimum distance classifier with three classes using the following training data: Then classify the test vector [1.0 2.0]𝑇with the trained classifier. Which class does this vector belong to?
A. Class 1.
B. Class 2.
C. Class 3.
D. indecision
Train an ANN as an R-category discrete perceptron training algorithm of a three class classifier using a three discrete bipolar perceptron network. Chosen initial weight vectors and y vectors are:𝒘𝟝 𝟝 = [ −𝟓 𝟝 𝟒 ], 𝒘𝟝 𝟝 = [ 𝟎 −𝟝 𝟝 ], 𝒘𝟑 𝟝 = [ −𝟗 𝟝 𝟎 ], 𝒚𝟝 = [ 𝟝𝟎 𝟝 −𝟝 ], 𝒚𝟝 = [ 𝟝 −𝟓 −𝟝 ] , 𝒚𝟑 = [ −𝟓 𝟓 −𝟝 } The final correct weights???
Н��) 𝑤1 = [ −5 1 4 ], 𝑤2 = [ 0 −1 2 ], 𝑤3 = [ −9 1 0 ]
Н��) 𝑤1 = [ 5 3 5 ], 𝑤2 = [ 0 1 2 ], 𝑤3 = [− 9 1 0 ]
Н��) 𝑤1 = [ 6 −1 3 ], 𝑤2 = [ 0 1 −2 ], 𝑤3 = [ −9 1 0 ]
D) 𝑤1 = [ 5 3 5 ], 𝑤2 = [ 0 −1 2 ], 𝑤3 = [ −9 1 0 ]
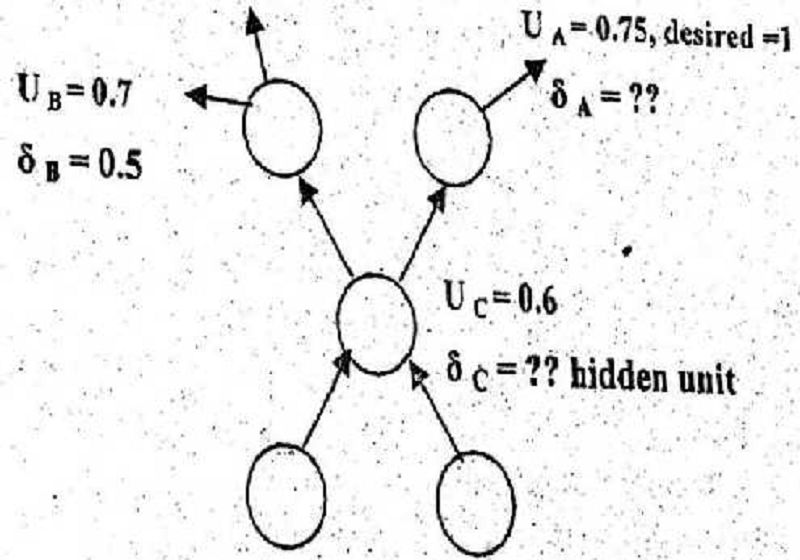
Assume continuous unipolar sigmoid function in opposite fig. (Part of backpropagation network). The values of б𝑨 ? ?.
A. 0.032,
B. 0.0469
C. 0.0469,
D. 0.054
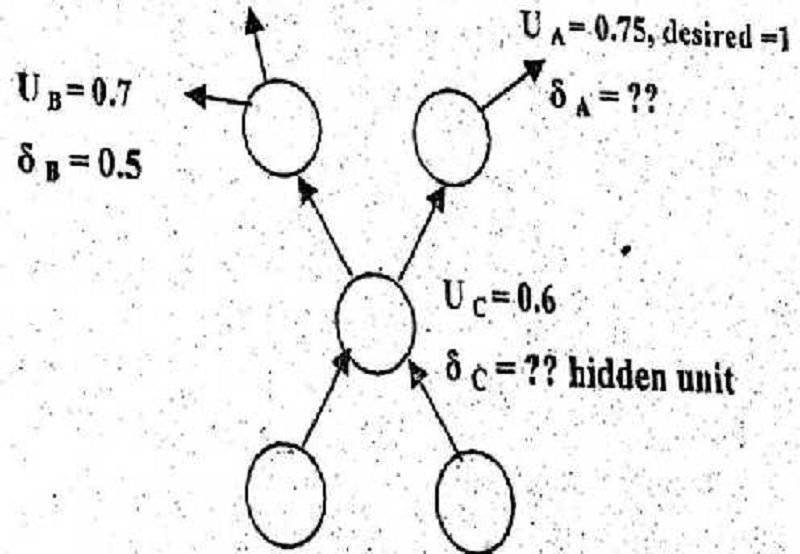
For the above question, the value of б𝑪 ??
A. 0.376
B) -0.384
C) 0.055
D) 0.2
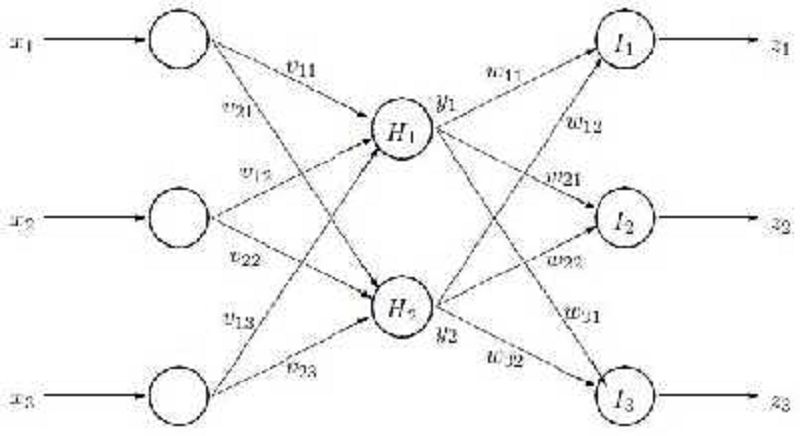
A training pattern, consisting of an input vector x = [𝒙𝟝; 𝒙𝟝; 𝒙𝟑] 𝑻 and desired outputs t = [𝒕𝟝; 𝒕𝟝; 𝒕𝟑]𝑻 , is presented to the following neural network. What is the usual sequence of events for training the network using the backpropagation algorithm?
A. (1) calculate yj = f(Hj ), (2) calculate zk = f(Ik), (3) update wkj , (4) update vji.
B. (1) calculate yj = f(Hj ), (2) calculate zk = f(Ik), (3) update vji, (4) update wkj .
C. (1) calculate yj = f(Hj ), (2) update vji, (3) calculate zk = f(Ik), (4) update wkj .
D. (1) calculate zk = f(Ik), (2) update wkj , (3) calculate yj = f(Hj ), (4) update vji.
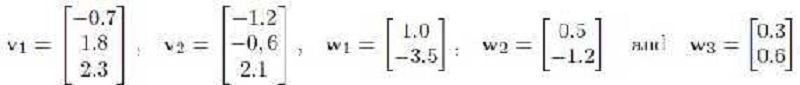
After some training, the units in the neural network of question(46) have the following weight vectors: Assume that all units have sigmoid activation functions and that each unit has a bias = 0 (zero). If the network is tested with an input vector x = [𝟝. 𝟎, 𝟑. 𝟎, 𝟝. 𝟎]𝑻 then the output of the first hidden neuron y1 will be
A. -2.1
B. 0.1091
C. 0.5000
D. 0.9982
For the same neural network described in questions (46) and (47), the output of the second hidden neuron y2 will be
A. -2.1
B. 0.1091
C. 0.5000
D. 0.9982
For the same neural network described in questions (46) and (47), the output of the first output neuron z1 will be
A. 0.61635
B. 0.5902
C. 0.5910
D. 0.6494
For the same neural network described in questions (3-1)and (3-2), the output of the third output neuron z3 will be
A. 0.3649
B. 0.5902
C. 0.5910
D. 0.6494
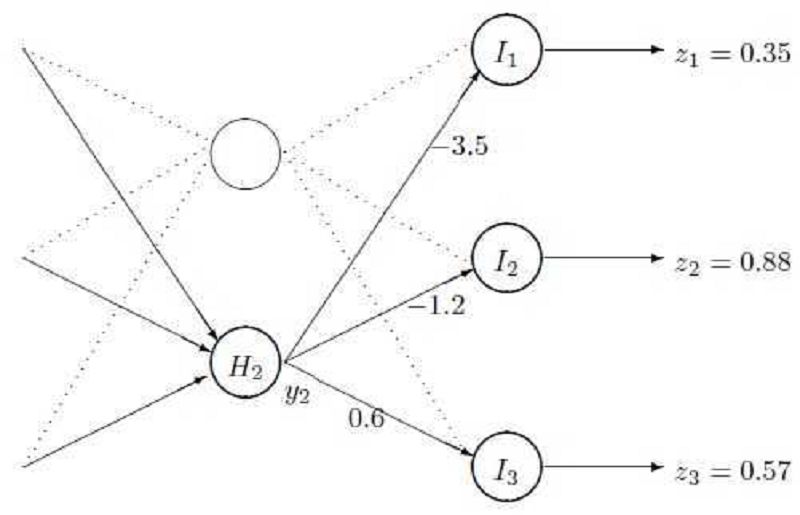
The following figure shows part of the neural network described in questions (46) and (47). In this question, a new input pattern is presented to the network and training continues as follows. The actual outputs of the network are given by z = [𝟎. 𝟑𝟓, 𝟎. 𝟖𝟖, 𝟎. 𝟓𝟕]𝑻 and the corresponding target outputs are given by t = [𝟝. 𝟎, 𝟎. 𝟎, 𝟝. 𝟎]𝑻 . The weights w12, w22 and w32 are also shown below. For the sigmoid activation function. What is the error for each of the output units?
A. δ output 1 = 0.4225, δ output 2 = −0.1056, and δ output 3 = 0.1849.
B. δ output 1 = 0.1479, δ output 2 = −0.0929, and δ output 3 = 0.1054.
C. δ output 1 = −0.4225, δ output 2 = 0.1056, and δ output 3 = −0.1849.
D. δ output 1 = 0.1479, δ output 2 = −0.0929, and δ output 3 = −0.1054.
For the hidden units of the same network. What is the error for hidden unit 2 given that its activation for the pattern being processed is currently y2 = 0.74?
A. δ hidden 2 = −0.2388
B. δ hidden 2 = 0.066
C. δ hidden 2 = −0.3429
D. δ hidden 2 = −0.066
A training pattern, consisting of an input vector x = [x1, x2, x3]T and desired outputs t = [t1, t2, t3]T, is presented to the following neural network. What is the usual sequence of events for training the network using the backpropagation algorithm?
A. (1) calculate yj = f(Hj ), (2) calculate zk = f(Ik), (3) update wkj, (4) update vji.
B. (1) calculate yj = f(Hj ), (2) calculate zk = f(Ik), (3) update vji, (4) update wkj.
C. (1) calculate yj = f(Hj ), (2) update vji, (3) calculate zk = f(Ik), (4) update wkj.
D. (1) calculate zk = f(Ik), (2) update wkj, (3) calculate yj = f(Hj ), (4) update vji.
After some training, the units in the neural network of question 22 have the following weight vectors: v1 = ⎡ ⎣ −0.7 1.8 2.3 ⎤ ⎦, v2 = ⎡ ⎣ −1.2 −0, 6 2.1 ⎤ ⎦, w1 = 1.0 −3.5 , w2 = 0.5 −1.2 and w3 = 0.3 0.6 . Assume that all units have sigmoid activation functions given by f(x) = 1 1 + exp(−x) and that each unit has a bias θ = 0 (zero). If the network is tested with an input vector x = [2.0, 3.0, 1.0]T then the output of the first hidden neuron y1 will
2.1000
0.1091
0.5000
0.9982
For the same neural network described in questions 22 and 23, the output of the first output neuron z1 will be
0.0570
0.2093
0.5902
0.6494
0.1091
For the same neural network described in questions 22 and 23, the output of the third output neuron z3 will be
0.0570
0.2093
0.5902
0.6494
For the same neural network described in questions 22 and 23, the output of the second hidden neuron y2 will be
2.10000
0.1091
0.5000
0.9982
The following figure shows part of the neural network described in questions 22 and 23. In this question, a new input pattern is presented to the network and training continues as follows. The actual outputs of the network are given by z = [0.35, 0.88, 0.57]T and the corresponding target outputs are given by t = [1.00, 0.00, 1.00]T. The weights w12, w22 and w32 are also shown below where wkj is the change to the weight from unit j to unit k, η is the learning rate, δk is the error for unit k, and f(net) is the derivative of the activation function f(net). For the sigmoid activation function given in question 23, the derivative can be rewritten as What is the error for each of the output units?
A. δoutput 1 = 0.4225, δoutput 2 = −0.1056, and δoutput 3 = 0.1849.
B. δoutput 1 = 0.1479, δoutput 2 = −0.0929, and δoutput 3 = 0.1054.
C. δoutput 1 = −0.4225, δoutput 2 = 0.1056, and δoutput 3 = −0.1849.
D. δoutput 1 = −0.1479, δoutput 2 = 0.0929, and δoutput 3 = −0.1054.
What is the error for hidden unit 2 given that its activation for the pattern being processed is currently y2 = 0.74?
A. δhidden 2 = −0.2388
B. δhidden 2 = −0.0660
D. δhidden 2 = 0.0660
E. δhidden 2 = 0.2388
Which of the following techniques is NOT a strategy for dealing with local minima in the backpropagation algorithm?
A. Add random noise to the weights or input vectors during training.
C. Train and test using the hold-one-out strategy.
B. Train using the Generalized Delta Rule with momentum.
D. Test with a committee of networks.
Training with the “1-of-M” coding is best explained as follows:
C. Set the target output to 1 for the correct class, and set all of the other target outputs to 0.
A. Set the actual output to 1 for the correct class, and set all of the other actual outputs to 0.
B. Set the actual outputs to the posterior probabilities for the different classes.
D. Set the target outputs to the posterior probabilities for the different classes.
The input vector to the network is x = [x1, x2, x3]T , the vector of hidden layer outputs is y = [y1, y2]T , the vector of actual outputs is z = [z1, z2, z3]T , and the vector of desired outputs is t = [t1, t2, t3]T. The network has the following weight vectors: v1 = ⎡ ⎣ 0.4 −0.6 1.9 ⎤ ⎦, v2 = ⎡ ⎣ −1.2 0.5 −0.7 ⎤ ⎦, w1 = 1.0 −3.5 , w2 = 0.5 −1.2 and w3 = 0.3 0.6 . Assume that all units have sigmoid activation functions given by f(x) = 1 1 + exp(−x) and that each unit has a bias θ = 0 (zero). If the network is tested with an input vector x = [1.0, 2.0, 3.0]T then the output y1 of the first hidden neuron will be A. -
2.300
0.091
0.993
0.644
Assuming exactly the same neural network and the same input vector as in the previous question, what is the activation I2 of the second output neuron?
0.353
0.596
0.674
0.387
For the hidden units of the network in question 31, the generalized Delta rule can be written as vji = ηδjxi where vji is the change to the weights from unit I to unit j, η is the learning rate, δj is the error term for unit j, and xi is the ith input to unit j. In the backpropagation algorithm, what is the error term δj?
A. δj = f(Hj)(tk − zk).
C. δj = f(Hj) k δkwkj.
D. δj = f(Ik) k δkwkj.
B. δj = f(Ik)(tk − zk).
For the output units of the network in question 31, the generalized Delta rule can be written as wkj = ηδkyj where wkj is the change to the weights from unit j to unit k, η is the learning rate, δk is the error term for unit k, and yj is the jth input to unit k. In the backpropagation algorithm, what is the error term δk?
A. δk = f(Hj)(tk − zk).
B. δk = f(Ik)(tk − zk).
C. δk = f(Hj) k δkwkj.
D. δk = f(Ik) k δkwkj.
Which of the following equations best describes the generalized Delta rule with momentum?
A. pwkj(t + 1) = ηδkyj + αf(Hj)yj(t)
pwkj(t + 1) = ηδkyj + αpwkj(t)
pwkj(t + 1) = ηδkyj + αδkyj(t)
pwkj(t + 1) = αδkyj(t)
The following figure shows part of the neural network described in question 31. A new input pattern is presented to the network and training proceeds as follows. The actual outputs of the network are given by z = [0.32, 0.05, 0.67]T and the corresponding target outputs are given by t = [1.00, 1.00, 1.00]T. The weights w12, w22 and w32 are also shown below For the output units, the derivative of the sigmoid function can be rewritten as f (Ik) = f(Ik)[1 − f(Ik)]. What is the error for each of the output units?
δoutput 1 = 0.1480, δoutput 2 = 0.0451, and δoutput 3 = 0.0730.
δoutput 1 = 0.1084, δoutput 2 = 0.1475, and δoutput 3 = 0.1054.
δoutput 1 = 0.4225, δoutput 2 = −0.1056, and δoutput 3 = 0.1849.
δoutput 1 = 0.1084, δoutput 2 = 0.1475, and δoutput 3 = 0.1054.
For the hidden units, the derivative of the sigmoid function can be rewritten as f (Hj) = f(Hj)[1 − f(Hj )]. What is the error for hidden unit 2 given that its activation for the pattern being processed is currently y2 = 0.50? A. δhidden
δhidden 2 = −0.4219
δhidden 2 = −0.0677
δhidden 2 = −0.1321
δhidden 2 = 0.0481
{"name":"Selected topics in computers", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"Test your knowledge of pattern classification, neural networks, and machine learning concepts with our comprehensive quiz! This quiz contains 68 carefully crafted questions designed to challenge your understanding of the selected topics in computers.Key Features:Multiple choice questionsCovers a wide range of topicsIdeal for students and enthusiasts alike","img":"https:/images/course2.png"}