
AI eksamen 2023
Choose the correct option:
Classification -> continuous data
Regression -> discrete data sets
Clustering -> unknown data set
Decision Tree -> Only discrete data
Suppose you have created a machine learning model which detects cat species. You tested the model in your development and test environemnt and it worked fine. You launched the code in production but there, some users are using the model to test kitten images. The model fails on kitten images. What can you do to fix it ?
Choose production as the only distribution and dont work with test or dev
Choose dev and test sets from the same distribution as production distribution
Choose dev and test from the same distribution
It is considered that Artificial Intelligence is the
Fourth industrial revolution
Third industrial revolution
Sixth industrial revolution
Fifth industrial revolution
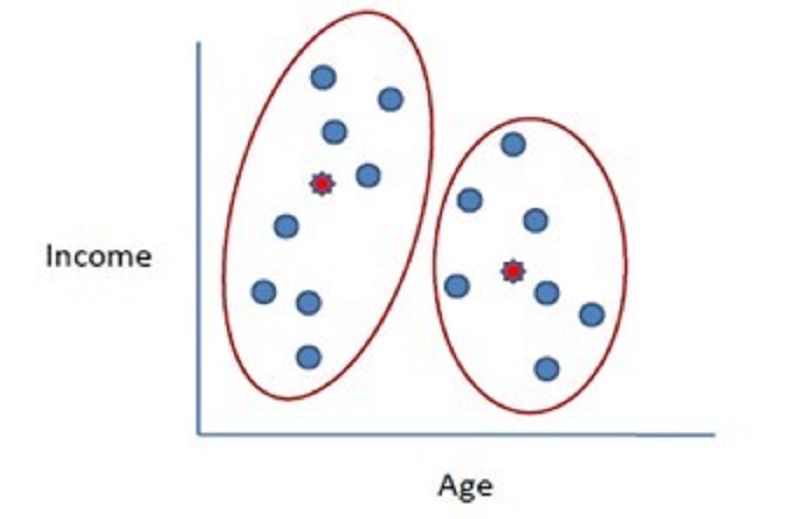
What kind of algorithm is the following:
Mean shift clustering algorithm
Apriopi algorithm
K-Means algorithm
What is a Turing test in Artificial Intelligence?
Turing test determines if a machine is capable of thinking like a human being.
Turing test determines if a human is capable of thinking like a machine.
Turing test determines if a machine is capable of acting like super computers.
Prompt engineering impacts AI model's performance by:
Expanding its training data
Increasing its computational speed
Enhancing the relevance and accuracy of its responses
Changing its underlying algorithms
Amazon had been working on a recruitment tool which uses AI for decision making (meaning which candidate should be called for an interview). However, the machine-learning specialists uncovered a big problem: their new AI recruiting system prioritized CVs of men over women. For some reason, the system taught itself that male candidates were preferable over female candidates. It penalized resumes that included the gender “women". This led to the failure of that tool. Theoretically speaking, what kind of problem was this ?
Data Exploration issue
Data Privacy issue
AI access issue
AI Bias issue
The transformer model, introduced in 'Attention is All You Need' (2017), is known for:
Reducing the need for large datasets
Its efficiency in processing sequential data
Simplifying neural network architectures
Its application in robotics
In AI, what is the 'singularity' often referred to?
The convergence of different AI technologies
The point where AI surpasses human intelligence
The creation of the first AI model

Which type of machine learning is shown in this image ?
Supervised learning
Reinforcement learning
Recomender systems
Unsupervised learning
Which of these is a key feature of 'Large Language Models' like GPT and BERT?
They are capable of understanding and generating human-like text
They are mainly used for image recognition tasks
They have a limited token range for processing language
They primarily focus on structured data analysis
What does a classification model do ?
Predicts real number responses such as changes in temperature, date, or time
Predicts the class of the data
None of the above
Clusters responses in groups based on similarity, to find patterns
Which of the following is a key characteristic of a transformer model in natural language processing?
It is based on Naive Bayes classification.
It relies on an attention mechanism.
It uses reinforcement learning.
It primarily utilizes decision trees.
You want to improve sales of your online store. You realize that people who buy books also buy pencils. This is just a theory but you want to test it out. What kind of algorithms can you use to try this out?
Clustering algorithms
Supervised algorithms
Association algorithms
The correlation between the number of years an employee has worked for a comany and the salary of the employee is 0.75. What can be said about employee salary and years worked ?
There is no relationship between salary and years worked
Individuals that have worked for the company the longest have higher salaries
The majority of employees have been with the company a long time
Individuals that have worked for the company the longest have lower salaries
Chatbots and Voice assistants (Siri, Alexa, Google assistant) are examples of:
Super AI
Narrow AI
General AI
Regression models are used with
Continuous data
Random data
none of the above
What is the maximum number of hyperplanes one can use
n dimensional
3 dimensional
2 dimensional
10 dimensional
What is the primary function of the K-means algorithm in machine learning?
Clustering
Classification
Regression
Reinforcement Learning
Suppose you are given a data set of customer complaints in Norwegian. The data set is labelled. You are now given a task to understand how angry or happy the customers are in those complaints. What kind of algortihms would you use ?
Classification
Regression
Clustering
While working with creating Artificial Intelligence applications, In which area do AI programmers spend most of their time ?
A.I programming
ML OPS
Model development
Data processing (cleaning, labeling etc)
Algorithm which does not consider relationships between features is:
Logistic regression
Linear regression
Support vector machines
Naive Bayes
Where do we primarily use data labeling ?
Reinforcement learning
Supervised learning
Unsupervised learning
Infrared sensors detect infrared energy that is emitted by one's body heat. When hands are placed in the proximity of the sensor, the infrared energy quickly fluctuates. This fluctuation triggers the pump to activate and dispense the designated amount of sanitizer. This is an example of:
Automated machine
AI machine
Deep Learning machine
Choose the correct option:
Regression -> discrete data sets
Decision Tree -> Only discrete data
Classification -> continuous data
Clustering -> unknown data set

The figure below an example of :
Feature engineering
Data labeling
Data annonimization
Synthetic data generation
Which country got the most private investments (for startups) in Artifical Intelligence (in 2018) in terms of per capita (dollar per person) ?
China
Israel
Unites states
Singapore
What kind of algorithm assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature
Linear regression
Polynomial regression
Naive Bayes algortihm
Logistic regression
Which of the following is a common use of unsupervised learning?
Detect outliers
Determine if meaningful relationships can be found in a dataset
Evaluate the likely performance of a supervised learning model
Determine a base set of inoput attributes for supervised learning
What is TRUE for a machine learning algorithm ?
It is harder to train the first 90% than the remaining 10%
None of the above.
It is harder to train the remaining last 10% than the first 90%
Suppose you are given a data set of X ray images of covid patients. The data set is not labelled and you dont have the opportunity to label it. You are now given the task to identify if the patient has covid or not. What kind of algortihm would you use ?
Clustering
Classification
Regression
Supose you are given the task to predict the high price for Tesla stock for the next day. You need data for atlast 15 years and you only have data for the last 5 years. How will you get that missing data ?
Data annonimization
Feature engineering
Synthetic data
Data warehousing
Identify which of the following is incorrect about the unsupervised learning-based model.
It lets make predictions and improves the algorithms on its own.
The algorithm itself analyzes the data set and determines relationship within that data.
The labelled data is fed with some rules by the developers.
We can provide a very large data set.
The output of a sigmoid function (for classification algoithms) has a range from
0 to 1
0 to 10
0 to 100
0 to 1000
Which statement is true about outliers ?
Outliers should be identified and removed from the data set
Outliers should be part of the test data set but should not be present in the training data
Outliers should be part of the training data set but should not be present in the test data
The nature of the problem determines how outliers are used
You have a data set for 1 million entries. For practical reasons, you do not have the time to label this data set. You need to find relationships between the data. What kind of technique will you use?
Association
Classification
Clustering
Supervised algorithms
Suppose that you are given the previous tax information of all individuals and you now have to develop an algorithm which predicts how much tax will they submit next year. Which type of algorithm would you use ?
Regression
Classification
Association
Clustering
What does the term 'overfitting' refer to in machine learning?
When a model performs too well on the training data but poorly on new data
When a model is too simple to capture the underlying pattern
When a model performs poorly on the training data
When a model requires excessive computational resources
Logistic regression is a ____ regression technique that is used to model data having a ____ outcome.
nonlinear, binary
linear, numeric
nonlinear, numeric
linear, binary
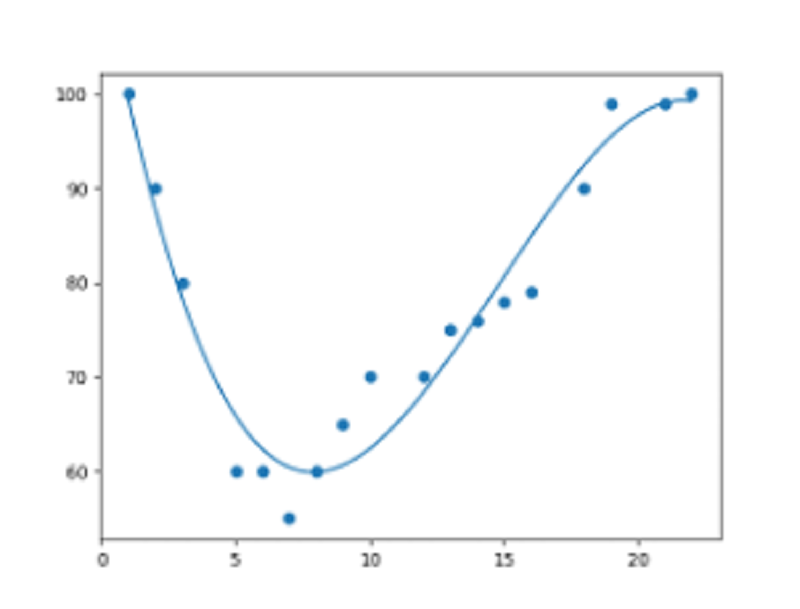
The following image is an example of
Linear regression
Polynomial regression
While creating an A.I algorithm, you need some data which does not exist. Which method will you use to obtain this data ?
Data preparation
Feature engineering
Synthetic data
Data anonimization
The process of collecting new attributes from an existing data (to train a machine learning model) is called:
Data labeling
Data mining
Feature engineering
Data wrangling
What is 'Prompt Engineering' in the context of AI?
The design and input of instructions to an AI model
The method of programming AI algorithms
The technique of optimizing AI model parameters
The process of building AI hardware
In Machine learning, Linear Regression falls within the category of:
Supervised learning
Recommender systems
Reinforcement learning
Unsupervised learning
Suppose you have to build a machine learning model to predict the price of housing market in Norway. What kind of models would you choose?
Classification models
Regression models
Reinforcement models
Is it normal to use the 70% train and 30% test data ratio when data set is big ?
Yes
No
What type of A.I is a recommendation system? (e.g used by Facebook, Amazon, Netflix etc)
Super A.I.
Narrow A.I.
General A.I.
The major reason behind the increased use of Artifical intelligence today is due to
Cloud computing
Powerful processors
Availability of increased data
Increased connectivity between devices
All of the above
What is NOT valid for a hyperplane ?
Hyperplanes work with support vector machines
They are boundaries that help classify data points
We can only use maximum 2 hyperplanes for any number of features
What is a Generative Adversarial Network (GAN)?
A database management system
A network for optimizing data storage
A pair of neural networks competing to improve data generation
A tool for analyzing large language models
In the context of AI, what does the term 'GAN' stand for?
General Algorithm Network
Generative Adversarial Network
Generic AI Node
Global Analysis Network
What is a 'token' in the context of Natural Language Processing (NLP)?
An algorithm used for language translation
A basic unit of text, such as a word or a part of a word
A type of neural network architecture
A method for encrypting text data
Choose the correct order of an AI project cycle.
Problem Scoping -> Data Acquisition -> Data Exploration -> Modelling -> Evaluation
Evaluation -> Problem Scoping -> Data Exploration -> Data Acquisition -> Modelling
Data Acquisition -> Problem Scoping -> Data Exploration -> Modelling -> Evaluation
Problem Scoping -> Data Exploration -> Data Acquisition -> Evaluation -> Modelling

In the following image the self driving car came to an abrupt stop. What do you think went wrong ?
The smiley face picture on the board is interpreted as a human face and the car cannot move
The human took the floppy drive out of the car and the car cannot move
Self driving cars have problems with blue color
A handful of stickers and graffitii have confused the car to misinterpret the sign
A data point which differs significantly from other observed data points is called
Synthetic data
Labelled data
Outlier
The type of machine learning which enables an agent to learn on its own through trial and error is called:
Recommender systems
Supervised learning
Unsupervised learning
Reinforcement learning
Which one of the following is the largest and fastest growing sector for AI-related global investment (2018-2019)?
Drug, cancer study
Facial Recognition
Autonomous driving
Robotic automation
{"name":"AI eksamen 2023", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"Choose the correct option:, Suppose you have created a machine learning model which detects cat species. You tested the model in your development and test environemnt and it worked fine. You launched the code in production but there, some users are using the model to test kitten images. The model fails on kitten images. What can you do to fix it ?, It is considered that Artificial Intelligence is the","img":"https://www.quiz-maker.com/3012/CDN/96-4739688/q16-dave3625-106112738-1646055639232.jpg?sz=1200"}
More Quizzes
Prima
834230
Cherokee County 9-1-1 S.O.P Quiz
320
Jewish News Quiz: Nov. 18, 2022
940
What "Creatura Obsoleta" House would YOU be in?
1470
Spider-Man Trivia - Can You Ace Every Question?
201020031
What Manga Should I Read? - Find Your Best Match
201018505
Spelling - How Do You Spell? Free Trivia
201021298
Lord of the Flies - Free Ultimate LOTF Challenge
201019926
Arrow - How Well Do You Know the TV Series?
201019719
Matching - Free Interactive Practice Online
201018420
Cooking Trivia - Free to Test Your Kitchen Smarts
201020138
What Architectural Style Is My House? Free
201018505