
ВНП Overfit
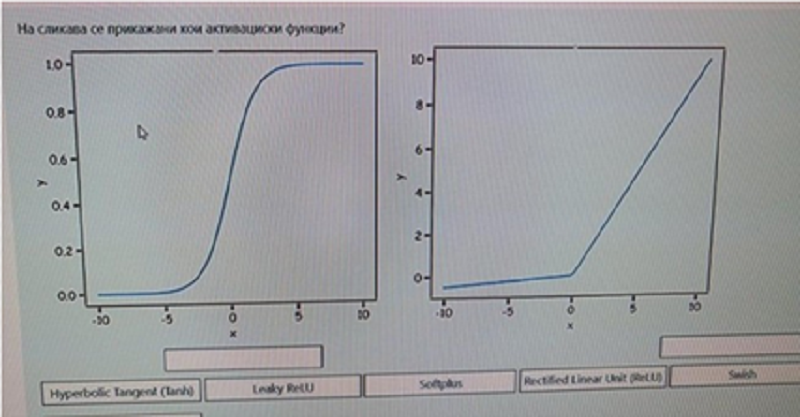
На сликава се прикажани кои активациски функции? (првото)
Hyperbolic Tangent (Tahn)
Leaky ReLU
Softplus
Rectified Linear Unit (ReLU)
Sigmoid
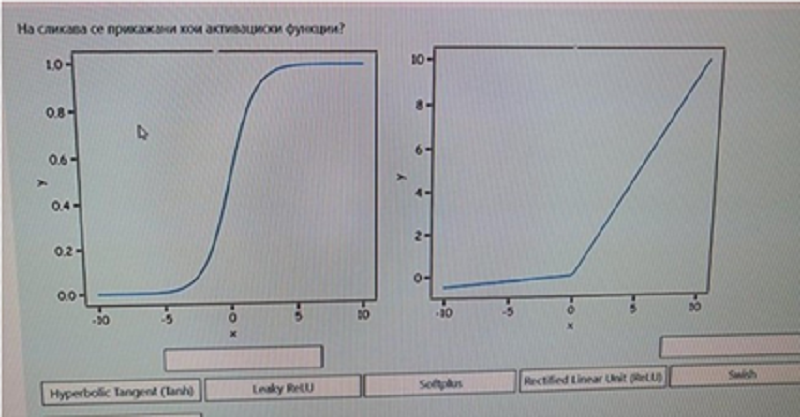
На сликава се прикажани кои активациски функции? (второто)
Hyperbolic Tangent (Tahn)
Leaky ReLU
Softplus
Rectified Linear Unit (ReLU)
Sigmoid


Што се Skip-grams?
N-grams кои се појавуваат во дадена реченица но не се појавуваат во дадениот контекст
Множество од не-последователни зборови (со одредено поместување), кои се појавуваат во некоја реченица
Стоп зборовите кои се појавуваат најчесто
Множество од сите зборови во реченицата
На кои од наведените модели за кластирање потребно е да се наведе бројот на кластери?
К-Means Clustering
AffinityPropagation Clustering
DBCAN Clustering
Agglomerative Clustering
Кои од наведените параметри се дел од хиперпараметрите за тренирање на XGBoost моделот?
N_estimators
Min_depth
Learninr_rate
Max_depth
Кои мерки ги користиме за сличност помеѓуи два кластера?
Бројот на елементи кои се наоѓаат во кластерите
Сличноста помеѓу два случајно избрани елементи од двата кластера
Најмалата различност помеѓу два елементи од кластерите
Сличноста помеѓу центроидите на двата кластера
Кои особености ги има Преносното учење (Transfer Learning)?
Врши пренос на моментите во друга невронска мрежа
Овозможува подобрување на перформансите
Може да научи преносно значење на зборовите
Врши пренос на испуштенисте јазли (drop-out) во друга невронска мрежа
Користи означени податоци од други или сродни области
Колку често можат да се ажурираат тежините кај невронските мрежи?
Ажурирање во серии (batch)
Ажурирање во случајно расфрлани мини-серии (mini-batches)
Ажурирање после секој примерок во множество за обука
Ажурирање во моменти
Ажурирање во конволуции
За што се користи Latent Dirichlet Allocation(LDA) алгоритмот?
Topic Modeling
Part-of-Speech (POS) tagging
Named Entity Recognition
Open Information Extraction
Word2vec како основа за креирање на Embeddings користи:
N-grams
Part of speech tagging
Skip-grams
One-hot embeddings
Што претставува хиперпараметарот n_estimatiors = 5 во XGBoost модел?
5 процесори да се искористат за тренирање на моделот
5 внатрешни јазли во дрвото на одлука
5 дрва на одлука кои паралелно ќе се изградат
5 листа на дрвото на одлука
Кои се предности на Long Short-term Memory (LSTM) мрежите?
Можноста за учење на долги низи
Потреба од мала меморија
Краткотрајно бришење од меморијата
Брзо учење при обука
Кај Наивните Баесови класификатори, за атрибути Ai за дадена класа C може да претпоставиме:
Условна зависност меѓу атрибутите, за таа класа
P(A1,A2,…,An|C) = P(A1|C) x P(A2|C) – P(An|C)
Условна независност меѓу атрибутите, за таа класа
P(A1,A2,…,An|C) = P(A1|C) + P(A2|C) ↔ P(An|C)
Кое од наведените можат да се користат како критериуми за прекин на понатамошното делење на јазли кај дрвата за одлучување (Stopping Conditions)?
Ако бројот на примероци што припаѓаат на дадена класа го надмине дозволениот број
Ако сите примероци во јазелот припаѓаат на истата класа
Ако бројот на циклуси надмине даден праг
Ако бројот на примероци во под-јазлите спадне под даден праг (min_samples_leaf)
Ако бројот на јазлите во дрвото надмине даден праг
Кои од следниве репозиториуми/библиотеки се користат за едноставно споделување на претренирани NLP модели?
HuggingFace Transformers library
PyTorch Hub
GitHub
TensorFlow-Hub
Што претставува поимот отфрлање (dropout) во контекст на невронски мрежи?
Бришење од меморијата при тестирање
Случајно поставување на активацијата и тежините на врските на некои неврони на нули
Трајно бришење од меморијата.
Откривање на недостатоци и нивно отфрлање
Кои се предности на Двонасочните LSTM мрежи (Bi-directional LSTM)?
Обично се подобри од еднонацочните рекурентни и LSTM мрежи
Побрзи се при обучувањето
Не бараат пристап до сите податоци однапред
Го зимаат предвид поширокото значење на контекстот
Каква димензионалност треба да е влезно тренирачко множество кај LSTM невронска мрежа?
2D
3D
1D
Kаков вид на учење се реализира кај Автоенкодерите ?
Нагледувано (supervised)
Полу-нагледувано(semi-supervised)
Само-нагледувано(self-supervised)
Со поттикување(reinforcement)
Кај Обработката на природни јазици се среќаваат следниве задачи:
Категоризација на теми
Препознавање на векторски претстави на зборовите (word embeddings)
Извлекување на контекстни зборови (skip-grams)
Препознавање на именувани нешта
Во кој случај би било најдобро да се употреби Sigmoid како излезно ниво кај невронските мрежи?
Кога влезовите во мрежата се дискретни вредности
Кога како мрежа за пресметка на загуба во мрежата се користи MSE (Mean Squared Error)
Кога бројот на влезови е поголем од бројот на излези во нервонската мрежа
Кога сакаме да добиеме побрзо процесирање на резултатите на GPU
Кога имаме бинарна класификација
Во кој случај би било најдобро да се употреби Softmax како излезно ниво кај невронските мрежи?
Кога имаме класификација во повеќе од две класи
Кога сакаме да добиеме по брзо процесирање на резултатите на GPU
Кога како мерка за пресметка на загуба во мрежата се користи MSE
Кога бројот на влезови е поголем од бројот на излези во невронската мрежа
Кога имаме длабока невронска мрежа
Нека е дадена реченицата: “It was a bright cold day in April, and the clocks were striking” Skip-gram со големина на прозорец три за зборот day e:
a bright cold
In April, and
Was bright cold April clocks were
A bright cold in April and
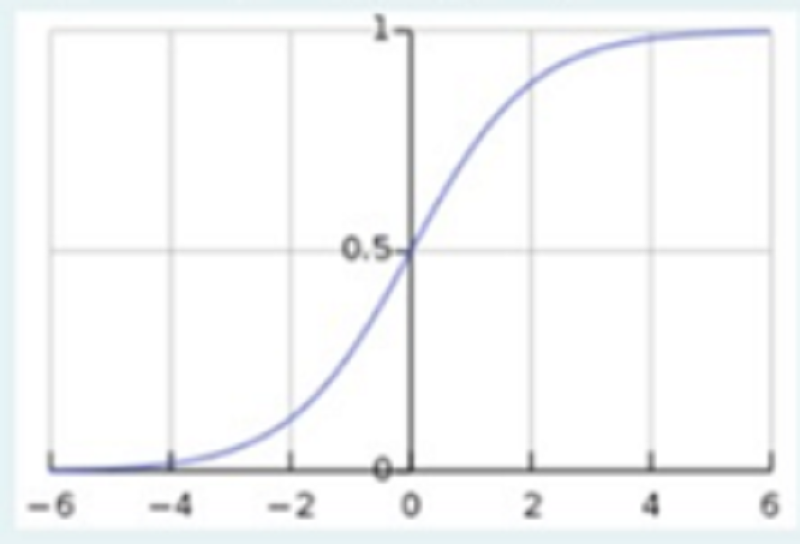
Која активациска функција е претставена на графикот?
ReLU
Sigmoid
Tanh
Leaky ReLU
Што е точно за моделот seq2seq?
Крајниот скриен слој на енкодерскиот дел е влезен слој за декодерскиот дел
Обуката се одвива како и кај другите Рекурентни невронски мрежи
Предноста на seq2seq е што целото значење на реченицата е претставено во крајниот скриен слој на енкодерскиот дел.
При тестирањето се генерираат збор по збор, се додека не се добие на излез знак за крај на реченицата
Кои карактеристики треба да ги има активациската функција кај невронските мрежи?
Да има некаква нелинеарност
Да овозможи градиентите да останат доволно големи и преку неколку скриени слоја
Да дава активација само за позитивни влезови
Да е заоблена
. Кои од наведените карактеристики се новитети кај Трансформер моделите?
Positional embeddings
Self Attention layer
Tokenization
Feedforward Network
Еден од најдобрите јазични модели BERT се потпира на трансформер архитектура. Кој дел од трансформер архитектура се користи во BERT?
Decoder
Encoder
Decoder + Encoder
Првите 9 нивоа од Encoder делот
Еден од најдобрите јазични модели GPT-2 се потпира на трансформер архитектура. Кој дел од трансформер архитектура се користи во GPT-2?
Decoder
Encoder
Првите 9 нивоа од Encoder делот
Decoder + Encoder
{"name":"ВНП Overfit", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"На сликава се прикажани кои активациски функции? (првото), На сликава се прикажани кои активациски функции? (второто), На прикажана слика е дадена шема за кој вид на учење со ансамбли?","img":"https://www.quiz-maker.com/3012/CDN/97-4787636/picture1.png?sz=1200"}