
Ib111
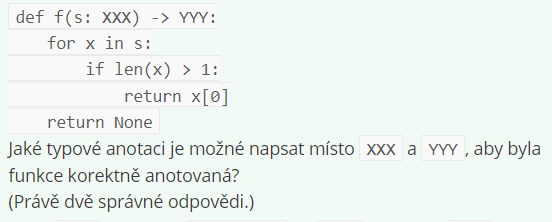
Za XXX doplníme list[str], za YYY doplníme str
Za XXX doplníme list[str], za YYY doplníme char | None
Za XXX doplníme list[list[int]], za YYY doplníme int
Za XXX doplníme list[list[int]], za YYY doplníme int | None
Za XXX doplníme list[str], za YYY doplníme str | None
Za XXX doplníme list[list[str]], za YYY doplníme str
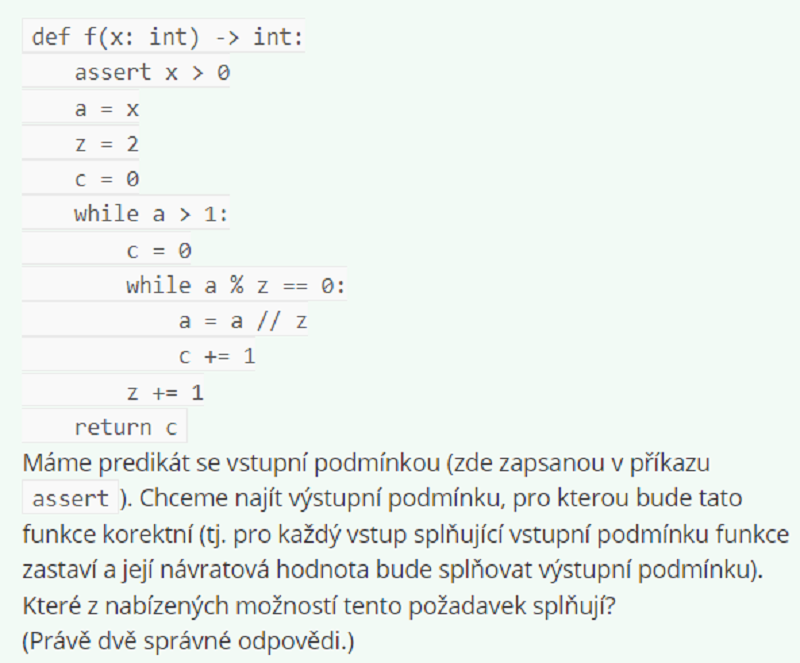
X < 2 or c >= sqrt(x)
X >= 3 ** c
X % 2 == 0 or x >= 3 ** c
X >= 2 ** c
X >= 121 or x <= 7 ** c
X >= 121 or x < 7 ** c


Data1 = sorted(data2)
Return data < [17]
Data = data + [42]
Result = [data1, data2]
Equal = (data1 == data2)
Data.insert(- len(data) // 2, - len(data) // 2)

Není predikát, protože modifikuje seznamy v proměnných nums1 a nums2
Není predikát, protože pro stejný vstup může vrátit různé výstupy.
Není predikát, protože nikdy nevrátí hodnotu False.
Není predikát, protože modifikuje parametr nums.
Je predikát.
Není predikát, protože jako vstup bere datový typ množina a práce s množinami nikdy není čistá.


Je čistá.
Není čistá, protože pracuje s řetězci.
Není čistá, protože má jiný vedlejší efekt.
Není čistá, protože modifikuje parametr data, a to tak, že mění jak klíče, tak hodnoty ve slovníku.
Není čistá, protože modifikuje parametr data, a to tak, že mění klíče ve slovníku, zatímco hodnoty nechává původní.
Není čistá, protože modifikuje parametr data, a to tak, že mění hodnoty ve slovníku, zatímco klíče nechává původní.

B == {1: {2}, 3: {4, 7}}
A == {1: {2}, 3: {7}}
A == {1: {2}, 3: set()}
A == {1: {2}, 3: {4, 7}}
B == {1: {2}, 3: {7}}
B == {1: {2}, 3: set()}

Žádná z ostatních možností není správná.
Ceil(num / 2.0 * -2.0)
Round(num / 2.0 * -2.0)
Trunc(num / 2.0 * -2.0)
Num / 2.0 * -2.0
Floor(num / 2.0 * -2.0)


Právě tvrzení C
Právě tvrzení B a C
Právě tvrzení B
Právě tvrzení A
Právě tvrzení A a B
Právě tvrzení A a C




(not a and b) or (not b and c) or (not c and a)
True
B or c
B and (not a or not c)
A or b or not c
B or (a and c)



Skončí s nějakou jinou chybou.
Skončí s chybou at least one argument of / must be a float na řádku A.
Skončí bez chyby.
Skončí s chybou ZeroDivisionError na řádku A.
Skončí s chybou ZeroDivisionError na řádku B.
Skončí s chybou ZeroDivisionError na řádku C.

Není čistá, protože pro různé vstupy vrací různé výstupy.
Je čistá.
Není možné rozhodnout, protože záleží na tom, co bude v parametru data.
Není čistá, protože pro stejné vstupy vrací různé výstupy.
Není čistá, protože modifikuje seznam data.
Není čistá, protože má nějaký jiný vedlejší efekt.


Tuple[int] | tuple[str] | tuple[float]
Tuple[int | str | float]
Tuple[int, str, int]
Tuple[int, str, float]
Tuple(int, str, float)
Tuple[int, str, float] | None

Operátor násobení v Pythonu zapisujeme pomocí znaku +.
Datová strukura ntice (tuple) smí obsahovat položky různých typů.
Abstraktní datová struktura zásobník funguje na principu LOFI (low fidelity), tedy při výběru prvku dostaneme vždy ten s nejnižší hodnotou.
Každou koncově rekurzivní funkci je možné ekvivalentně napsat bez rekurze.
Operátor dělení v Pythonu zapisujeme pomocí znaku %.
V algoritmu Insert Sort opakovaně procházíme celý seznam a prohazujeme špatně uspořádané dvojice sousedních prvků.



Data.pop(3)
Has_answer = (42 in data)
New = data + [21]
Data.reverse()
Value = (data[0] + data[-1] + data[len(data) // 2]) // 3
Data.insert(-1, -1)

MyClass.do_something()
Do_something(my_obj)
My_obj = do_something()
My_obj.do_something()
My_obj.do_something
Nic takového není možné provést.


Round(num / 10.0)
Num / 10.0
Floor(num / 10.0)
Ceil(num / 10.0)
Trunc(num / 10.0)
Žádná z ostatních možností není správná.

Není čistá, protože používá metodu append.
Není čistá, protože se uvnitř vytváří nový seznam.
Není čistá, protože modifikuje parametr num.
Je čistá.
Není čistá, protože modifikuje parametr data.
Není čistá, protože modifikuje oba své parametry.


Data = data + [0]
Is_less = data1 < data2
Data.reverse()
Data = data.copy()
Data.append(data1)
Data[len(data) // 2] = data1


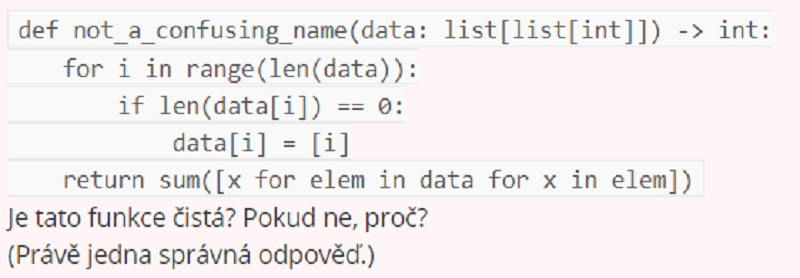
Není čistá, protože modifikuje parametr data.
Není čistá, protože má jiný vedlejší efekt.
Není čistá, protože pro stejné vstupy vrací různé výstupy.
Není čistá, protože používá funkci sum, která nemusí být čistá.
Je čistá.
Není čistá, protože uvnitř používá metodu copy.

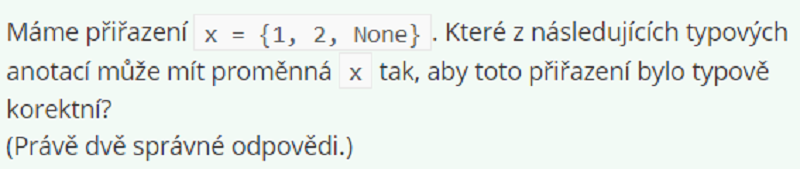
Dict[int, int, None]
Set[int, int, None]
Set[int] | None
Set[int | None]
Set[int] | set[None]
Set[int | None] | None


A or b or (c and a)
A or b or c
A or not b or not c
A or (not b and c)
A or b or not c
(a or b) and (a or c)

Power = one ** 2 + two ** 2
Power = one ^ 2 + two ^ 2
Lst.remove(last[-1])
Power = (one + two) ^ 2
Lst.pop()
Power = (one + two) ** 2

Operátor celočíselného dělení zapisujeme v Pythonu jako /.
Položky v datové struktuře slovník (dict) se skládají ze dvou částí: klíče a hodnoty; přitom klíče musí být unikátní, zatímco hodnoty nikoliv.
Eukleidův algoritmus pro výpočet největšího společného dělitele je založen na principu půlení intervalu.
Abstraktní datová struktura fronta funguje na principu LIFO (last input, first output), tedy prvky vkládáme do atributu last a odebíráme z atributu first.
Každou rekurzivní funkci je možné ekvivalentně napsat bez rekurze.
V algoritmu Select Sort opakovaně procházíme celý seznam a prohazujeme špatně uspořádané dvojice sousedních prvků.

Ceil(num / 10)
Round(num / 10 + 0.5)
Floor(num / 10 + 0.9)
(num + 9) // 10
(num + 5) // 10
(num + 1) // 10



Není predikát, protože modifikuje parametr name.
Je predikát.
Není predikát, protože pro stejný vstup může vrátit různé hodnoty.
Není predikát, protože používá řetězce.
Není predikát, protože nikdy nevrátí hodnotu True.
Není predikát, protože má nějaký jiný vedlejší efekt.

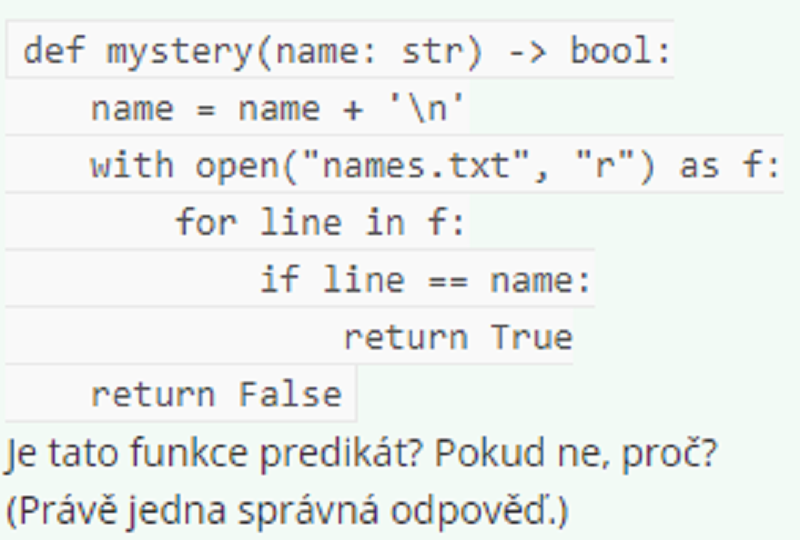
Není predikát, protože modifikuje parametr name.
Není možné rozhodnout, protože záleží na obsahu souboru names.txt.
Není prefikát, protože pro stejný vstup může vrátit různé hodnoty.
Není predikát, protože nemá vstupní parametr typu bool.
Není predikát, protože používá řetězce.
Je predikát.

Algoritmus binárního vyhledávaní je zalložen na principu půlení intervalu.
Aritmetické výrazy s operátory + a * se vyhodnocují líně, tj. Nejprve se vyhodnotí levý operand a teprve pokud je to nutné, vyhodnotí se I ten pravý.
Abstraktní datová struktura zásobník funguje na principu LIFO (last in, first out), teda pri vybrání prvku ze zásobníku dostaneme ten naposledy vložený.
Klíče v datové strukture slovník jsou vždy sestupne usporádany.
Klíče v datové strukture slovník jsou vždy vzestupne usporádany.
V algoritmu Insert Sort opakovane hledáme maximum dosud nezpracované části seznamu a prohadzujeme je s prvkom na spávné pozici.



Num + 7.2
Ceil(num + 7.2)
Trunc(num + 7.2)
Round(num + 7.2)
Floor(num + 7.2)
Žádná z ostatních možností není správná.

False
A and not b and not c
(not a or not c) and not b
Not a or not b or not c
Not a and not b and not c
(not a and not b) or (not b and not c) or (not c and not a)

[1, 2, 1, 3, 1, 2, 4]
[3, 2]
[1, 2, 3, 4]
[1, 2, 1, 2, 3, 1, 2, 3, 4]
[1, 2, 3, 1, 2, 4]
[1, 2, 1, 3, 1, 4]

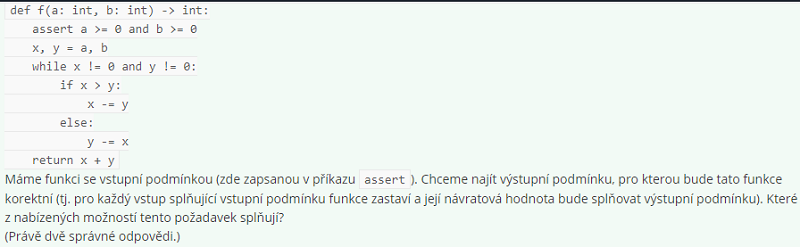
A >= b or x + y <= a
X + y < a or x + y < b
X + y <= min(a, b)
A % (x + y) == 0
A == 0 or x + y <= a
X + y >= 0


Tuple[bool] | tuple[int] | tuple[str]
Tuple[bool, int, str]
Tuple[bool, int, char]
Tuple[bool, int | None, str | None]
List[bool | int | str]
Tuple[bool | int | str]


Data[0] = [3]
Data[0].append(3)
Assert len(data) > 0
Students[uco] =""
Students.get(uco)
Return students[uco]
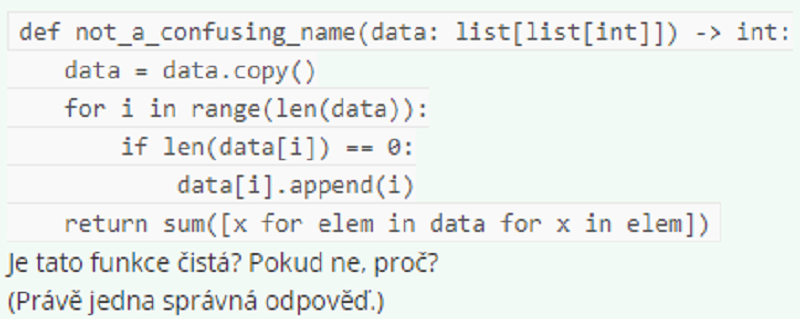
Není čistá, protože pro stejné vstupy vrací ruzne výstupy.
Není čistá, protože má jiný vedlejší efekt.
Není čistá, protože modifikuje parametr data.
Není čistá, protože uvnitr používa metodu copy.
Není čistá, protože používa funkci sum, ktorá nemusí byt čistá.
Je čistá.

Data = data1 + data2
Return data1 == data2
Data.insert(-3, 3)
Ints = [1 if x > 0 else 0 for x in data]
Data.pop(len(data) - 2)
Data.insert(3, 3)



V konštantnom čase sa vyhodnotí: (2 správne odpovede).
Answer = True in data and 1 + 1 == 3
Data.pop(3)
First = sorted(data)[0]
Data[3] = data[-3]
Length = len(data)


2 správne odpovede
A = [[7, 2], [3, 4]]
A = [[1, 2], [5, 6]]
A = [[7, 2], [5, 6]]
B = [[7, 2], [5, 6]]
B = [[1, 2], [5, 6]]
B = [[1, 2], [3, 4]]

Je predikát.
Není predikát, protože modifikuje parametr a.
Není predikát, protože modifikuje parametr b.
Není predikát, protože pro ruzne vstupy muze vratit ruzne vystupy
Není predikát, protože nemusí vracať bool.
Není predikát, protože používa rekurziu.
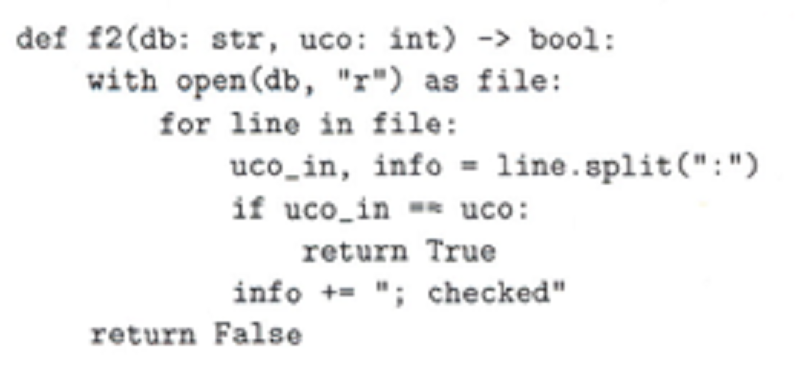
Je čistá.
Není čistá, protože muze mat vedlejši efekty.
Není čistá, protože modifikuje parametr db.
Není čistá, protože modifikuje parametr uco.
Není čistá, protože pracuje s retazcemi.
Není čistá, protoze vracia inu hodnotu ako None.


Mystery(4, [])
[4, 3, 2, 1, 1, 2, 3, 4]
[4, 3, 2, 1, 0, 1, 2, 3, 4]
[4, 3, 2, 1, -1, -2, -3, -4]
[4, 3, 2, 1, 0, -1, -2, -3, -4]
[-4, -3, -2, -1, 1, 2, 3, 4]
[1, 2, 3, 4]

V konštantnom čase se vyhodnotí: (2 správne odpovede).
Data.pop(3)
New_data = data + [21]
Has_answer == (42 in data)
Data.reverse()
Value = (data[0] + data[-1] + data[len(data) // 2] // 3
Data.insert(-1, -1)

Je čistá.
Není čistá, protože mení klíče slovníku uloženého v parametru data.
Není čistá, protože mení hodnoty slovníku uloženého v parametru data.
Není čistá, protože má nejaký jiný vedlejší efekt.
Není čistá, protože pre ruzne vstupy muze vratit ruzne vystupy.
Není čistá, protože nevrací bool.

Je čistá.
Není čistá, protože má nejaký jiný vedlejší efekt.
Není čistá, protože pre ruzne vstupy muze vratit ruzne vystupy.
Není čistá, protože vrací dva ruzne typy.
Není čistá protoze pouziva funkcii sorted
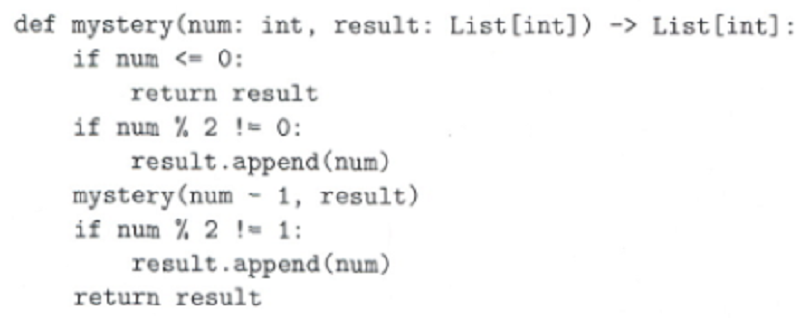
Mystery(5, [])
[5, 3, 1, 2, 4]
[1, 2, 3, 4, 5]
[5, 3, 1, 4, 2]
[1, 3, 5, 2, 4]
[5, 3, 1, -1, 0, 2, 4]
[5, 4, 3, 2, 1]

V konštantnom čase sa vyhodnotí: (2 odpovede).
Answer = False and (true in data)
Data.pop(0)
New.data = data + [True]
Data.sort()
Data.insert(0, -1)
Data.append(17)

Je čistá.
Není čistá, protože má iné vedlejší efekty.
Není čistá, protože pracuje s retezcemi.
Není čistá, protože modifikuje parametr xs.
Není čistá, protože nevrací bool.
Není čistá, protože pre rovnake vstupy muze vracat ruzne vystupy

Je čistá.
Není čistá, protože má iné vedlejší efekty.
Není čistá, protože pracuje s retezcemi.
Není čistá, protože modifikuje parametr s.
Není čistá, protože pre rovnake vstupy muze vracat ruzne vystupy.
Není čistá, protože nevrací bool.


Mystery(4, [])
[1, 2, 3, 1, 4, 1, 2]
[1, 2, 1, 3, 1, 4]
[1, 2, 1, 3, 1, 4, 1, 2]
[1, 2, 3, 4, 1, 2]
[]
[1, 2, -1, 3, 1, 4, -1, 2]

2 správne odpovede
A = [("C", 4), ("B", 1)]
B = [("A", 2), ("A", 3)]
A = [("A", 2), ("A", 3)]
B = [("C", 4), ("B", 1)]
A = [("A", 2), ("C", 4)]
B = [("A", 2), ("B", 1)]

Je predikát.
Není predikát, protože modifikuje parametr data.
Není predikát, protože modifikuje parametr limit.
Není predikát, protože vrací typ bool.
Není predikát, protože pre rovnake vstupy muze vracat ruzne vystupy.
Není predikát, protože modifikuje oba parametry.

Není predikát, protože modifikuje parametr nums.
Je predikát.
Není predikát, protože pre rovnake vstupy muze vracat ruzne vystupy.
Není predikát, protože vrací typ bool.
Není predikát, protože používa funkcii sorted.
Není predikát, protože používa funkcii sort().

{"name":"Ib111", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"","img":"https://www.quiz-maker.com/3012/CDN/97-4759204/81.png?sz=1200"}
More Quizzes
Civics Quiz
63100
Computerized Accounting Quiz 2
16833
One Avenue Pub Quiz 3
53260
210
Kendrick Lamar - Test Your Rap Knowledge
201020910
Advertising: Test Your Ad Knowledge Free Online
201022622
What Does LMAO Stand For? - Test Your Slang IQ
201022477
LSU Trivia - Test Your Tigers Fan Knowledge
201025706
Teste para Saber o Sexo do Bebê Online: Menino ou Menina
201019117
Immaculate Reception - Oakland Raiders
201028442
What Does ESOP Stand For? Free ESOP Knowledge
201017464
Which Taylor Swift Album Are You? Take the Free
201020227