
ادعي لشهاب الدين انه ينجح عشان قاعد ٝي اسكندرية و مش عارٝ يذاكر
( PP )

Parallel Computing Challenge
Test your knowledge on parallel computing concepts with our engaging quiz! Dive into questions that span the fundamentals of parallel processing, memory architectures, and programming models.
Whether you're a student, a professional, or just someone interested in the world of computing, this quiz offers:
- 59 thought-provoking questions
- Multiple choice format
- Instant feedback on your answers
1-It is the simultaneous use of multiple compute resources to solve a computational problem?
A.Sequential computing
B.Parallel computing
C.None of these
D.Single processing
2-Here a single program is executed by all tasks simultaneously. At any moment in time, tasks can be executing the same or different instructions within the same program. These programs usually have the necessary logic programmed into them to allow different tasks to branch or conditionally execute only those parts of the program they are designed to execute.?
A.Single Program Multiple Data (SPMD)
B.Multiple Program Multiple Data (MPMD)
C.None of these
D.Von Neumann Architecture
3-Parallel computing can include?
A.Arbitrary number of computers connected by a network
B.Single computer with multiple processors
C.None of these
D.Combination of both A and B
4-Synchronous communication operations referred to?
A.It exists between program statements when the order of statement execution affects the results of the program.
B.It refers to the practice of distributing work among tasks so that all tasks are kept busy all of the time. It can be considered as minimization of task idle time.
C.Involves only those tasks executing a communication operation
D.None of these
5-These computer uses the stored-program concept. Memory is used to store both program and data instructions and central processing unit (CPU) gets instructions and/ or data from memory. CPU, decodes the instructions and then sequentially performs them.
A.Von Neumann Architecture
B.Single Program Multiple Data (SPMD)
C.Flynn’s taxonomy
D.None of these
6- The average number of steps taken to execute the set of instructions can be made to be less than one by following _______ .?
A.pipe-lining
B.sequential
C.ISA
D.super-scaling
7-Data dependence is?
A.It refers to the practice of distributing work among tasks so that all tasks are kept busy all of the time. It can be considered as minimization of task idle time.
B.It exists between program statements when the order of statement execution affects the results of the program.
C.Involves only those tasks executing a communication operation
D.None of these
8-In the threads model of parallel programming?
A.A single process can have multiple, concurrent execution paths
B.A single process can have single, concurrent execution paths.
C.None of these
D.A multiple process can have single concurrent execution paths.
9-in global sum examples of array of size [1000], to be written in parallel computing. The coordination involves?
A.communication
B.synchronization
C.load balancing
D.all above
10-Writing parallel programs with MPI dealing with?
A.distributed memory system
B.shared memory system
C.all of the above
D.A&B
11-Non-Uniform Memory Access (NUMA) is?
A.Here all processors have equal access and access times to memory
B.Here one SMP can directly access memory of another SMP and not all processors have equal access time to all memories
C.Here if one processor updates a location in shared memory, all the other processors know about the update.
D.None of these
12-Pipe-lining is a unique feature of _______?
A.RISC
B.ISA
C.CISC
D.IANA
13-A processor performing fetch or decoding of different instruction during the execution of another instruction is called ______ which can finish instruction in one clock cycle.?
A.parallel computation
B.pipe-lining
C.super-scaling
D.none of these
14-In order to run faster with more realistic graphic program we need?
A.rewrite our serial programs so that they’re parallel, so that they can make use of multiple cores
B.rite translation programs, that is, programs that will automatically convert serial programs into parallel programs
C.A and B
D.A or B
15-Task-parallelism ?
A.we partition the various tasks carried out in solving the problem among the cores
B.we partition the data used in solving the problem among the cores, and each core carries out similar operations on its part of the data
C.A&B
D.we partition the program among the cores
16-In shared Memory?
A.Changes in a memory location effected by one processor do not affect all other processors.
B.Changes in a memory location effected by one processor are randomly visible to all other processors.
C.Changes in a memory location effected by one processor are visible to all other processors
D.None of these
17-n the threads model of parallel programming?
A.A single process can have multiple, concurrent execution paths
B.A single process can have single, concurrent execution paths.
C.A multiple process can have single concurrent execution paths.
D.None of these
18-Uniform Memory Access (UMA) referred to?
A.Here all processors have equal access and access times to memory
B.Here one SMP can directly access memory of another SMP and not all processors have equal access time to all memories
C.Here if one processor updates a location in shared memory, all the other processors know about the update.
D.None of these
19-A pipeline is like ________?
A.house pipeline
B.an automobile assembly line
C.both a and b
D.a gas line
20-Non-Uniform Memory Access (NUMA) is?
A.Here if one processor updates a location in shared memory, all the other processors know about the update.
B.Here all processors have equal access and access times to memory
C.Here one SMP can directly access memory of another SMP and not all processors have equal access time to all memories
D.None of these
21-Pthreads: Processes threads deals with?
A.shared memory system
B.distributed memory system
C.A&B
D.all of the above
22- Parallel processing may occur?
A.in the instruction stream
B.in the data stream
C.both[a] and [b]
D.none of the above
23- in global sum examples of array of size [1000], to be written in parallel computing. The coordination involves?
A.communication
B.load balancing
C.synchronization
D.all above
24-The number and size of tasks into which a problem is decomposed determinesthe __?
A.dependency graph
B.granularity
C.task
D.decomposition
25-A feature of a task-dependency that determines the average degree of concurrency for a given granularity is its........ path?
A.ambiguous
B.difficult
C.easy
D.critical
26-ncreasing number of processors gives better results as the program parallels-------and serial part------?
A.100%,no serial
B.99% ,zero%
C.increase, decrease
D.100%, 0.1%
27-Which speed up could be achieved according to Amdahl’s Law for infinite number of processes if 5% of a program is sequential and the remaining part is ideally parallel?
A.50
B.5
C.Infinite
D.20
28-Massively Parallel -------?
A.Observed speedup of a code which has been parallelized, defined as: wall-clock time of serial execution and wall-clock time of parallel execution.
B.The amount of time required to coordinate parallel tasks. It includes factors such as: Task start-up time, Synchronizations, Data communications.
C.Refers to the hardware that comprises a given parallel system - having many processors.
D.None of these.
29-Distributed Memory--?
A.A computer architecture where all processors have direct access to common physical memory
B.It refers to network based memory access for physical memory that is not common
C.Parallel tasks typically need to exchange data. There are several ways this can be accomplished, such as through, a shared memory bus or over a network, however the actual event of data exchange is commonly referred to as communications regardless of the method employed
D.None of these
30-Asynchronous communications---?
A.It involves data sharing between more than two tasks, which are often specified as being members in a common group, or collective.
B.It involves two tasks with one task acting as the sender/producer of data, and the other acting as the receiver/consumer.
C.It allows tasks to transfer data independently from one another.
D.None of these
31-Instruction dependency can be solved by ---------------to enable parallel execution of instruction ?
A.Pipelining
B.Multithreading
C.Multiprocessors
D.None
32-Load balancing is------?
A.Involves only those tasks executing a communication operation
B.It exists between program statements when the order of statement execution affects the results of the program.
C.It refers to the practice of distributing work among tasks so that all tasks are kept busy all of the time. It can be considered as minimization of task idle time.
D.None of these
33-In shared Memory---?
A.Multiple processors can operate independently but share the same memory resources
B.Multiple processors can operate independently but do not share the same memory resources
C.Multiple processors can operate independently but some do not share the same memory resources
D.None of these
34-Granularity is-----?
A.In parallel computing, it is a qualitative measure of the ratio of computation to communication
B.Here relatively small amounts of computational work are done between communication events
C.Relatively large amounts of computational work are done between communication / synchronization events
D.None of these
35-Collective communication-----?
A.It involves data sharing between more than two tasks, which are often specified as being members in a common group, or collective.
B.It involves two tasks with one task acting as the sender/producer of data, and the other acting as the receiver/consumer.
C.It allows tasks to transfer data independently from one another.
D.None of these.
36-Cache Coherent is-----?
A.Here all processors have equal access and access times to memory.
B.Here if one processor updates a location in shared memory, all the other processors know about the update.
C.Here one SMP can directly access memory of another SMP and not all processors have equal access time to all memories.
D.None of these.
37-n designing a parallel program, one has to break the problem into discreet chunks of work that can be distributed to multiple tasks. This is known as--?
A.composition
B.Partitioning
C.Compounding
D.None of these
38-It distinguishes multi-processor computer architectures according to how they can be classified along the two independent dimensions of Instruction and Dat(A) Each of these dimensions can have only one of two possible states: Single or Multiple--?
A.Single Program Multiple Data (SPMD)
B.Flynn’s taxonomy
C.Von Neumann Architecture
D.None of these
39-Parallel Execution-----?
A.A sequential execution of a program, one statement at a time
B.Execution of a program by more than one process, with each process being able to execute the same or different statement at the same moment in time
C.A program or set of instructions that is executed by a processor.
D.None of these
40-Coarse-grain Parallelism--?
A.In parallel computing, it is a qualitative measure of the ratio of computation to communication
B.Here relatively small amounts of computational work are done between communication events
C.Relatively large amounts of computational work are done between communication / synchronization events
D.None of these
41----------------gives the theoretical speedup in latency of execution of a task at fixed execution time ?
A.Metcalfe’s
B.Moor’s
C.Amdahl’s
D.Gustafson’s
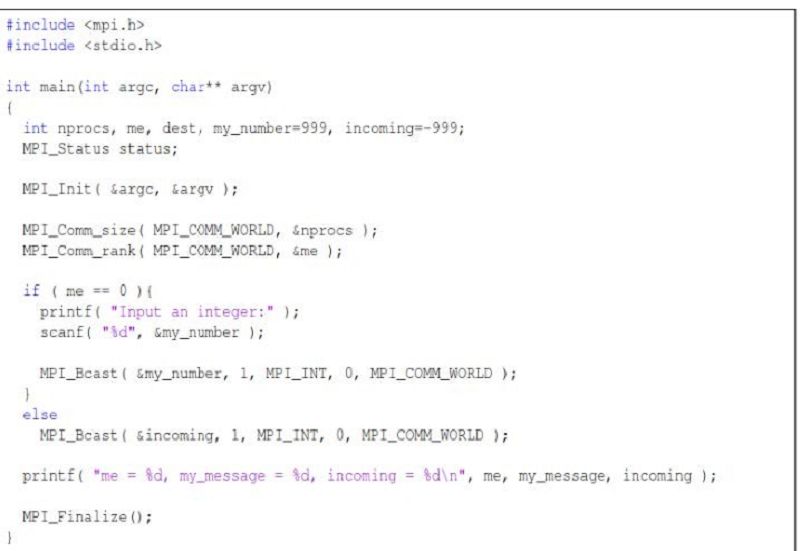
A.none
B.the root send messages from processors
C.the processors broadcast their value to root
D.the root receives values from the processors
43-The MPI is used for sending and receiving messages without cost?
True
False
44-MPI_Bcast----?
A.performs a barrier synchronization operation.
B.performs a broadcast operation.
C.determines the wall- time.
D.shuts down MPI and releases resources.
45-MPI_ send used for---?
A.Collect message.
B.receive message.
C.send message.
D.transfer message.
46-MPI_Comm_size---?
A.determines the number of processes.
B.performs a reduction operation.
C.initializes MPI.
D.determines a process's ID number (called its rank).
47-MPI_Init----?
A.Intialize MPI environment
B.Call Processes
C. Start MPI Program
D.Close MPI environment.
48-The number and size of tasks into which a problem is decomposed determines the ----?
A.fine-granularity.
B.sub-Task.
C.coarse-granularity
D.granularity.
49-MPI_Recv used for----?
A.Reverse message.
B.forward message.
C.Collect message.
D.Receive message.
50-MPI_Barrier---?
A.performs a barrier synchronization operation.
B.shuts down MPI and releases resources.
C.determines the wall- time.
D.performs a broadcast operation.
51-MPI_Wtime----?
A.determines the wall- time.
B.shuts down MPI and releases resources.
C.performs a barrier synchronization operation.
D.performs a broadcast operation.
52-he two operations that are reverse to each other are __________ , __________
A.MPI_Allgather().
B.MPI_Scatter().
C.MPI_Bcast
D.MPI_Gather().
53-MPI_Reduce---?
A.performs a reduction operation.
B.initializes MPI.
C.determines the number of processes.
D.determines a process's ID number (called its rank).
54-int MPI_Recv( void *buff, int count, MPI_Datatype datatype,int src, int tag, MPI_Comm comm, MPI_Status *status ) status is--?
A.holds information about the received message.
B.address where the data that is communicated.
C.rank of the source process, relative to the communicator given in comm.
D.the communicator that describes the group of processes.
55-MPI_Wtick-----?
A.performs a broadcast operation
B.determines the wall- time.
C.shuts down MPI and releases resources.
D.determines the length of a clock tick
56-In MPI Program MPI_char is the instruction for--?
A.Long char.
B.Unsign Char.
C.Unsign long char.
D.Sign char.
57-collects the send buffer contents of all processes and concatenates them in rank order into the receive buffer of the root process.?
A.call MPI_Bcast.
B.MPI_Scatter().
C.MPI_Allgather().
D.MPI_Gather().

A.root receives from all processors
B.different from broadcasting
C.processors receive from each others
D.root sends to all processors
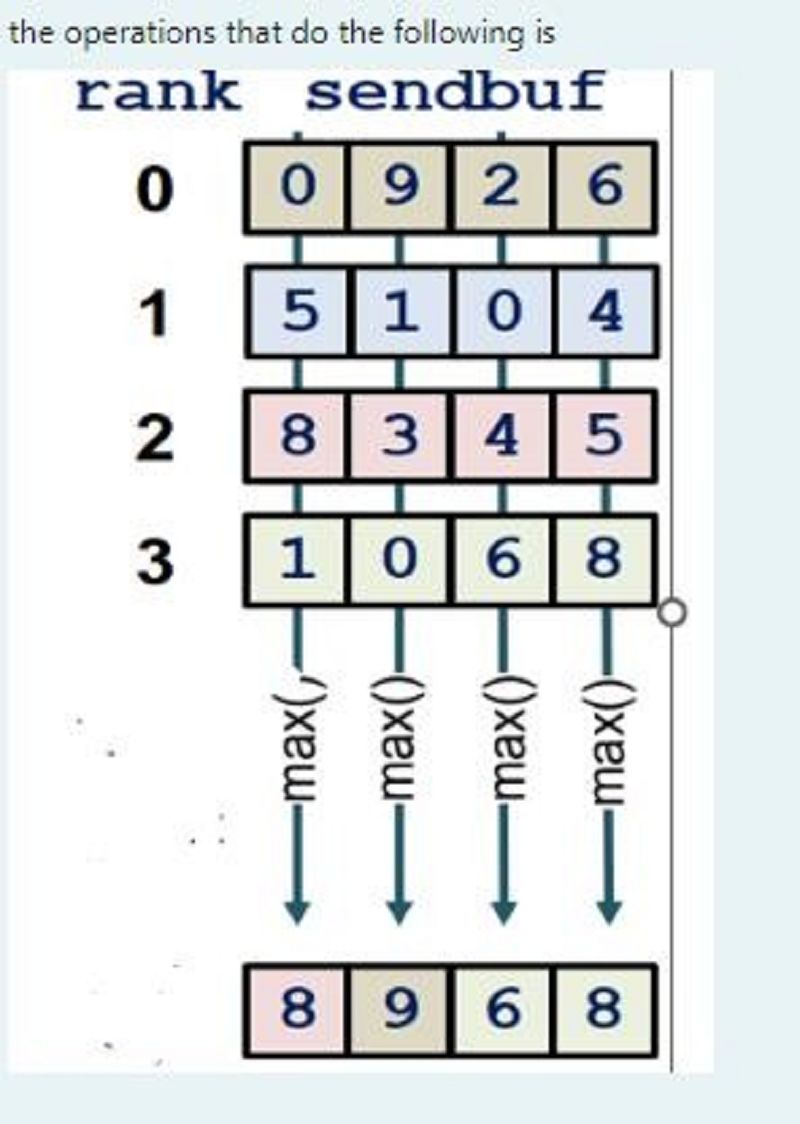
A.MPI_Bcast
B.MPI_Gather().
C.MPI_Max()
D.MPI_Reduce()
{"name":"ادعي لشهاب الدين انه ينجح عشان قاعد ٝي اسكندرية و مش عارٝ يذاكر ( PP )", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"Test your knowledge on parallel computing concepts with our engaging quiz! Dive into questions that span the fundamentals of parallel processing, memory architectures, and programming models.Whether you're a student, a professional, or just someone interested in the world of computing, this quiz offers:59 thought-provoking questionsMultiple choice formatInstant feedback on your answers","img":"https:/images/course5.png"}
More Quizzes
Supercomputers: subtitles
3276
Mapping Functions Quiz
15813
Civil Law Guessing Game
30150
Famous Photos by: Holden Griffith
100
My Type of Man - Find Your Ideal Match
201018430
EverFi Perfect Playlist Answers Practice - Free
201017418
Free Emotional Intelligence Test Online - Instant Results
201020925
What Soccer Position Should I Play? Take the Free
201021288
Utah Counties - How Many Can You Name?
201018346
Sleeping Beauty - Test Your Character Knowledge
201022775
Computer IQ: Hardware and Software - Free
201024739
Club Penguin Trivia - Test Your Knowledge
201022775