
CS121 Final
Which of the following is not a characteristic of the world-wide web (www)?
Large and dynamic corpus
There is information to avoid (spam, misleading and false information)
Mostly stable, long-living content
High linkage
Which of the following is not a characteristic of Information Retrieval (IR)?
Classic IR was originated in the scientific domain and library records.
Finding material of unstructured nature
Satisfies an information need from within large collections
Web IR mainly focuses on static content
Which of the following is not a property of popular web search engines?
Including spell check
Linking to resources (maps, images, etc) by guessing what the user is looking for
Suggesting alternatives searches
Not interpreting syntactic cues, such as math equations
Which of the following sentences is true regarding web search engines?
Recall refers to the relevance of the first few results
Precision refers to the number of relevant results that are presented
In general web IR, precision is more important than recall
Web search engines consider the web as a graph, where hyperlinks are nodes
Which of the following is not a mapping rule for tokens Canonicalization?
Removing characters such as hyphen, periods and accents.
Reducing all letters to lower case (case-folding)
Collapsing alternate spellings (colour -> color)
Keeping synonyms as different classes to include more diverse tokens
Which of the following statements is true with regards to Stemming and Lemmatization?
Both try to reduce morphological word variants to a single version
Lemmatization is easier to perform and does not require morphological analysis
Lemmatization reduces morphological variations of words to a common stem
Stemming removes inflection to arrive at base dictionary form of the word.
Consider the following sentence “I dance the Macarena song on the dance floor.” Which of the following statements is false?
Using assignment #1 methodology, the sentence contents 7 tokens
The sentence has 8 bigrams (i.e., 8 2-grams)
Dance (verb) and dance (adjective) are considered the same token
The sentence has 9 words. Therefore, we can find 93 trigrams (i.e., 729 3-grams)
Which of the following web page features is not a legitimate approach to perform search engine optimization (SEO)?
Age
Having relevant content, well written and organized.
Implementing web standards and good practices
Duplicating important content to make sure users find it.
Which of the following black hat techniques focuses on web re-directing (HTTP 302) to a different site?
Keyword Stuffing
Cloaking
Doorway Pages
Clicker bots
Which of the following web crawling issues is related to the client-side scripting?
Impolite crawler, which hits the same web too often.
Crawler traps
Data noise
Missed content
� If you were to create a robot (spider) to crawl the web, which of the following actions should you be considering to do?
Trying to be anonymous during the crawl to avoid privacy issues.
Ignoring sites’ crawling policies (robots.txt), so you don’t skip any content
Keeping your crawler’s raw data, and sharing the results publicly
Running your crawler while out on vacation, because that may take a few days.
Which of the following statements is true with regards to “Privacy Statement” and/or “Terms of Use”?
Both refer to the collection of users’ information
All web sites have Privacy Statement
All web sites have Terms of Use
Privacy Statement refers to which users’ data is collected by the web site.
Which of the following statements is false with regards to the typical hardware of a server?
Access to data in main memory (RAM) is much faster than access to data on disk.
Disk seeks are slow, mainly because the disk head is positioned each time.
CPU can process data during ram-disk data transfers, because of the System Bus.
Transferring many small chunks of data from disk to memory is faster than transferring a large chunk.
Which of the following statements is false with regards to an Inverted Index Construction?
Terms in the Dictionary are the direct result of tokenizing documents (collection).
A typical Inverted Index will consist of a Dictionary file and Posting Lists.
The Dictionary file will contain the terms sorted alphabetically.
The Posting Lists will consist of collections of documents ID (docID) for each term.
In lecture, we saw that in-memory index construction does not scale. Which of the following is the main reason?
The collection is always too large to store it in usual disks sizes.
We can’t store large collections in main memory, which is a constraint to scale up.
Main memory is cleared when the computer shuts down.
External sorting algorithms such as SPIMI cannot operate in main memory.
Which of the following is not a technique of BSBI (Blocked sort-based Indexing)?
Hashing terms (hash = termID) to save space
Keeping a record of (term, termID) in main memory.
Saving n blocks of (termID, docID) in main memory.
Merging postings into the final index.
Which of the following is not a reason to perform Index Compression?
Making the Dictionary small enough to keep in main memor
Reducing Postings lists to save memory and disk space.
Decreasing the time needed to read postings lists in disk (saving disk seeks).
Reduce the CPU processing time when reading the Dictionary.
Which of the following statements is false with regards to Collection Statistics?
The number of terms found increases with the number of tokens proportionally.
Zipf’s law is an empirical law to estimate the distribution of terms in a collection.
Heap’s law is an empirical law to estimate the number of terms in a collection.
N a large collection, one can find few very frequent terms and many rare terms
Which of the following statements is true regarding dictionary compression?
Blocking and Front-Coding techniques do not require Dictionary-as-a-string.
Regarding the number of terms for Blocking (k), a larger k is always best
Front-Coding consists of storing differences for terms with same prefix
Dictionary-as-a-string does not need the term pointers if there is no Blocking
Which of the following Posting Lists Compression codes does use a dedicated one bit as a continuation bit (c)?
Variable Byte (VB) code.
Gamma Code (bit-level compression).
Both Variable Byte (VB) code and Gamma Code (bit-level compression).
None.
� Imagine you have a collection of a million documents (N) with an average of 1,000 words per document and a total of M=500,000 terms (unique words). Which of the following statement is false regarding its Term-Document Incidence Matrix?
The matrix would be extremely sparse (most entries would be 0)
The matrix would consist of a distribution of 0 and 1 with dimension M by N
The matrix shows the term frequency (tf) of each term in each document.
Each column (vector) shows which terms are present in each document.
Which of the following statements is false with regards to Boolean Retrieval model?
It answers queries based on Boolean expressions (AND, OR and NOT)
It views documents as a set of terms.
It is very precise, as its queries need to meet a very specific condition.
It cannot combine two operators, such as “AND NOT” or “OR NOT”
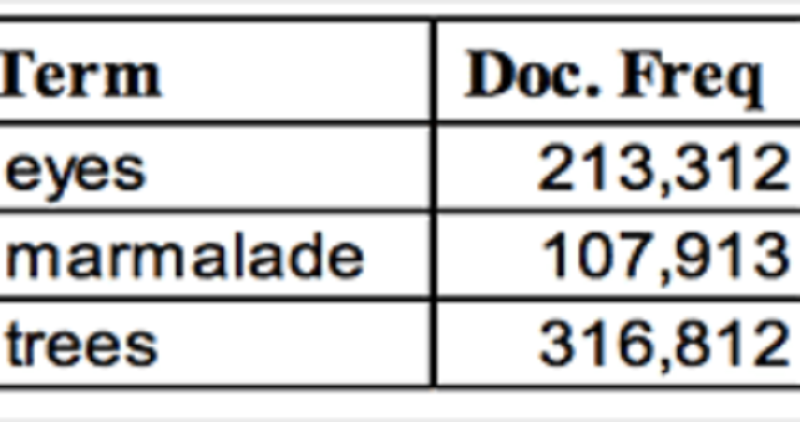
Select the most efficient processing order for the Boolean query Q. Q: “trees AND marmalade AND eyes”
(marmalade AND eyes) first, then merge with trees
(marmalade AND trees) first, then merge with eyes.
(trees AND eyes) first, then merge with marmalade.
Any combination would result in the same amount of operations.
Which of the following statements is false regarding the Boolean Retrieval model?
It does not perform query spell checking
It does not capture information about term position in the documents.
It does not consider document structure (zones in documents such headers).
It considers term frequency information to rank results.
Which of the following statements is false regarding the Ranked Retrieval model?
It returns an ordering over the (top) documents in the collection for a query.
It accepts free text queries as input (one or more words in a human language)
It works better (easier to use) than Boolean models for most users
Large result sets are an issue in Ranked Retrieval as we overwhelm users
Find the Jaccard coefficient (Jc) for the query and documents below. Query: top university (set q) Doc 1: university of California (set d1) Doc 2: best university in USA (set d2)
Jc(q,d1)=1/4, Jc(q,d2)=1/5
Jc(q,d1)=1/5, Jc(q,d2)=1/6
Jc(q,d1)=0, Jc(q,d2)=1/6
Jc(q,d1)=1/5, Jc(q,d2)=0
Which of the following statements is false with regards to the Term-document Count Matrix of a set of M terms in a collection of N documents?
�Each document is a count vector of dimension M consisting of natural numbers.
The term-document Count Matrix considers term frequency.
The term-document Count Matrix considers the position of terms in a document
This Term-document Count Matrix is also known as “bag of words” model
Mark the false statement with regards to the term frequency (tf)?
The tf is the number of times that a term occurs in a document
Relevance of a term in a document increases proportionally with its tf
The tf of a query is the sum of the tf of each of the terms in the query.
The tf of a query is 0 if none of the query terms is present in the document.
Mark the false statement with regards to the document frequency (df)?
Rare terms are more informative than frequent terms.
The df of a term t can be found as the length of the posting list of t.
Frequent terms are more informative than rare terms.
The df of a term t refers to the number of documents that contain t.
Which of the following statements is false with regards to the Vector Space Similarity?
Terms are axes of the space, which results in a high-dimensional space
Documents and queries can be presented as points or vectors in the space
The Euclidean distance query-document is a good approach to rank its similarity
Documents can be ranked according to their proximity to the query in the space.
Let K b the targeted top results of your search engine system, and N the number of documents of your collection/corpus. Which of the following aspects should you consider for efficient results ranking given a query?
(a) Choosing the top K results without sorting all N scores for the given query
(b) Avoiding computing all N scores for the given query.
You should consider both options (a) and (b).
None of the others.
When trying to compute cosines efficiently, the simplifications we can assume regarding the query would be:
(a) Assume each query term occurs only once in the query
(b) Do not normalize the query vector.
You should consider both simplifications (a) and (b).
None of the others.
When trying to compute cosines efficiently, which of the following strategies are not part of the Index Elimination technique?
Only considering documents containing many of the query terms.
Only considering documents containing at least one query term.
Only considering query terms with high-idf.
Only considering stop words with high-idf.
� Imagine you are constructing Tiered Indexes to improve the efficiency of your search engine. Which of the following statements is false?
You will break index up into tiers of decreasing importance
You can break the index by Authority or term frequency, among other scores
Using Authority to break the index, the same document may appear in different tiers
Using term frequency to break the index, the same document may appear in different tiers.
In lecture, we saw that Authority is a Static Quality Score of a document. Which of the following is not an Authority signal?
Wikipedia among websites.
Articles in certain newspapers.
A paper with many citations
A web page with high term frequency for a given query
Which of the following statements is false regarding the use of Parametric Indexes?
It is sometimes convenient to build range trees, for instance when storing dates.
Author, Title and Date of Publication are important fields/zones for papers
It is possible to encode zones in dictionary
It is not possible to encode zones in postings.
Based on the diagram of IR components that we saw in lecture, which of the following components is not an output of the Indexers module?
Metadata in Zone and Fields Indexes.
Inexact Top K Retrieval.
Tiered Inverted Positional Index
Query Parser.
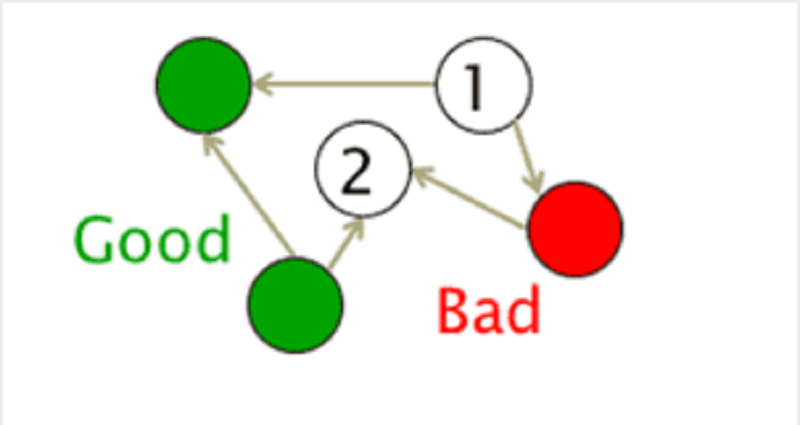
–Consider the following figure representing the web as a graph with good (green) and bad (red) pages/nodes in an interlinked structure. Which statement is true regarding the nodes “1” and “2”?
Both are bad.
Both are good.
�1” is good and “2” is bad.
2” is good and “1” is bad.
Mark the false statement with regards to the hub score [h(x)] and authority score [a(x)] of a page X when conducting Hyperlink-Induced Topic Search (HITS)?
Highest scores for h( ) and a( ) will define the hubs and authorities respectively.
Relative values of scores h( ) and a( ) need ~106 iterations to converge.
In the iterative part, both initial values for h(x) and a(x) can be setup to one.
Scaling factor of h( ) and a( ) does not matter, as we only consider the relative values
� Mark the false statement with regards to Hubs and Authorities?
A good hub page for a topic points to many authoritative pages for that topic
A good authority page for a topic is pointed to by many good hubs for that topic.
By using hub pages, we still cannot retrieve documents in other languages
Using hubs is best suited for “broad topic” queries rather than for page-finding queries
{"name":"CS121 Final", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"Which of the following is not a characteristic of the world-wide web (www)?, Which of the following is not a characteristic of Information Retrieval (IR)?, Which of the following is not a property of popular web search engines?","img":"https://cdn.poll-maker.com/18-733112/screen-shot-2017-06-11-at-6-54-57-pm.png?sz=1200-01219000000775005300"}