
NeuroData Training Quiz 2

NeuroData Training Quiz 2
Test your knowledge on machine learning concepts with our engaging NeuroData Training Quiz 2! This quiz features a variety of questions that cover essential topics in data science and machine learning.
Whether you're a student, a professional, or just someone interested in the field, this quiz is for you. Challenge yourself and check how well you understand the intricacies of data handling!
Which of the following hyper parameter(s), when increased may cause random forest to over fit the data? Number of Trees Depth of Tree Learning Rate
Only 1
Only 2
Only 3
1 and 2
2 and 3
1,2 and 3
Below are the 8 actual values of target variable in the train file. [0,0,0,1,1,1,1,1] What is the entropy of the target variable?
-(5/8 log(5/8) + 3/8 log(3/8))
5/8 log(5/8) + 3/8 log(3/8)
3/8 log(5/8) + 5/8 log(3/8)
5/8 log(3/8) – 3/8 log(5/8)
Let’s say, you are working with categorical feature(s) and you have not looked at the distribution of the categorical variable in the test data. You want to apply one hot encoding (OHE) on the categorical feature(s). What challenges you may face if you have applied OHE on a categorical variable of train dataset?
All categories of categorical variable are not present in the test dataset.
Frequency distribution of categories is different in train as compared to the test dataset.
Train and Test always have same distribution.
Both A and B
None of these
Which of the following options is/are true for K-fold cross-validation? 1- Increase in K will result in higher time required to cross validate the result. 2- Higher values of K will result in higher confidence on the cross-validation result as compared to lower value of K. 3- If K=N, then it is called Leave one out cross validation, where N is the number of observations.
1 and 2
2 and 3
1 and 3
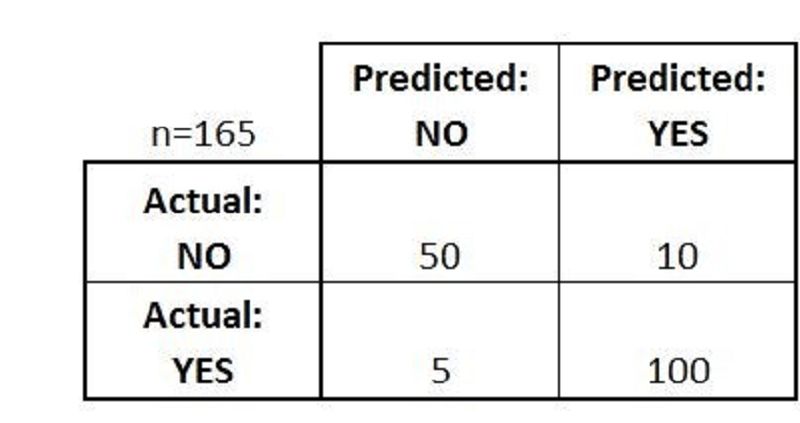
Imagine you are working on a project which is a binary classification problem. You trained a model on training dataset and get the below confusion matrix on validation dataset.Based on the above confusion matrix, choose which option(s) below will give you correct predictions? 1- Accuracy is ~0.91 2- Misclassification rate is ~ 0.91 3- False positive rate is ~0.95 4- True positive rate is ~0.95
1 and 3
2 and 4
1 and 4
2 and 3
For which of the following hyperparameters, higher value is better for decision tree algorithm? 1- Number of samples used for split 2- Depth of tree 3- Samples for leaf
1 and 2
2 and 3
1 and 3
1, 2 and 3
Can’t say
Which of the following is an example of a deterministic algorithm?
PCA
K-mean
None of the above
Imagine, you are working with “NeuroData” and you want to develop a machine learning algorithm which predicts the number of views on the articles. Your analysis is based on features like author name, number of articles written by the same author on NeuroData in past and a few other features. Which of the following evaluation metric would you choose in that case?1- Mean Square 2- Error Accuracy 3- F1 Score
Only 1
Only 2
Only 3
1 and 3
2 and 3
1 and 2
Adding a non-important feature to a linear regression model may result in. 1- Increase in R-square 2- Decrease in R-square
Only 1 is correct
Only 2 is correct
Either 1 or 2
None of these
{"name":"NeuroData Training Quiz 2", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"Test your knowledge on machine learning concepts with our engaging NeuroData Training Quiz 2! This quiz features a variety of questions that cover essential topics in data science and machine learning.Whether you're a student, a professional, or just someone interested in the field, this quiz is for you. Challenge yourself and check how well you understand the intricacies of data handling!","img":"https:/images/course3.png"}
More Quizzes
Deep Learning
20100
Big Data 1
94298
Starfleet Captain's Test
940
September 23 Sneaker Quiz
8415
Generations of Computers: Can You Ace Every Era?
201054210
Free Muscles: Back, Legs & Neck
201023765
Free Leadership Development Program
201025225
Mandy Musgrave: True Fan of South of Nowhere?
201032582
Which Hannah Montana Character Are You? Discover Your Match!
201029936
Am I Chill: Discover Your Inner Calm or Chaos
201029936
Free Active/Passive: I Ate a Piece of Chocolate Cake
201026931
Discover How Much Phone Storage You Really Need
201025003